
Discover connections and patterns with data mining analytics
Data mining enables you to uncover intriguing connections and patterns in datasets that might elude human intuition. For instance, a father was once surprised to receive various offers for products typically purchased during pregnancy – the supermarket had deduced before he did that his daughter was expecting. By leveraging machine learning, statistics, and database techniques, data mining provides highly sophisticated insights into your customers, processes, and products. However, data mining isn’t without controversy; ethical concerns can arise – like the embarrassment caused to the daughter in this story – and without a solid understanding of statistics, it’s easy to draw incorrect conclusions. In this article, we explain what data mining is, outline the six steps of the data mining process, share nine examples of successful applications, review popular data mining software, and provide practical tips to help you achieve meaningful results.
What is data mining?
 Data mining, artificial intelligence, and big data are often mentioned together, as are data mining, deep learning, data science, and predictive analytics. While these terms share similarities, they also have important differences. To avoid confusion, we use a clear and precise definition of data mining:
Data mining, artificial intelligence, and big data are often mentioned together, as are data mining, deep learning, data science, and predictive analytics. While these terms share similarities, they also have important differences. To avoid confusion, we use a clear and precise definition of data mining:
Data mining is the process of identifying connections, patterns, and correlations in structured data using machine learning, statistics, and database techniques.
The ultimate goal of data mining is to uncover new insights “hidden” within the data and transform them into actionable knowledge. This knowledge can then be used to make better decisions, optimize processes, and drive innovation. Data mining primarily focuses on the automated analysis of structured data to generate advanced insights, but it does not function in isolation. To achieve success, you need the following essential building blocks:
 Figure 1: A diagram illustrating the essential building blocks for data mining and its ultimate goal, better decision-making.
Figure 1: A diagram illustrating the essential building blocks for data mining and its ultimate goal, better decision-making.
- Data sources: select and extract data from reliable, high-quality sources
- Data warehouse: combine and integrate data from multiple sources
- Data discovery: analyze and thoroughly understand the data
- Data mining software: apply statistical and machine learning to the collected data
- Data visualization: present patterns and relationships visually for easy comprehension
- Better decisions: make data-driven decisions and continuously improve them
Although the diagram flows from bottom to top, we recommend starting with the decisions you aim to improve in your primary process, rather than beginning with the data sources. Establishing a clear goal at the outset ensures the right focus for your data mining project.
Where are the roots of data mining?
 The roots of data mining trace back to the 18th century, when Bayesian probability, probability theory, and regression analysis emerged as foundational elements of mathematics.
The roots of data mining trace back to the 18th century, when Bayesian probability, probability theory, and regression analysis emerged as foundational elements of mathematics.
However, the term “data mining” as a concept did not appear in database circles until the 1990s. Initially, it was formally known as Knowledge Discovery in Databases, or KDD, but over time, the term “data mining” became more commonly used.
Given this history and the inquisitive nature of data mining, it’s no surprise that “data discovery” is widely recognized as a synonym for data mining. In its broadest sense, “data science” serves as the overarching term for this field. Professionals in the industry or researchers in academia who engage in data mining and data science are naturally referred to as data scientists.
How does it differ from process mining?
Process mining and data mining are often confused in practice or, worse, grouped together. However, the differences between the two concepts far outweigh their similarities. Let’s start with the key similarities: both data mining and process mining fall under the broad category of Business Intelligence & Analytics. Additionally, both increasingly leverage machine learning algorithms to uncover hidden patterns, (causal) relationships, and anomalies.
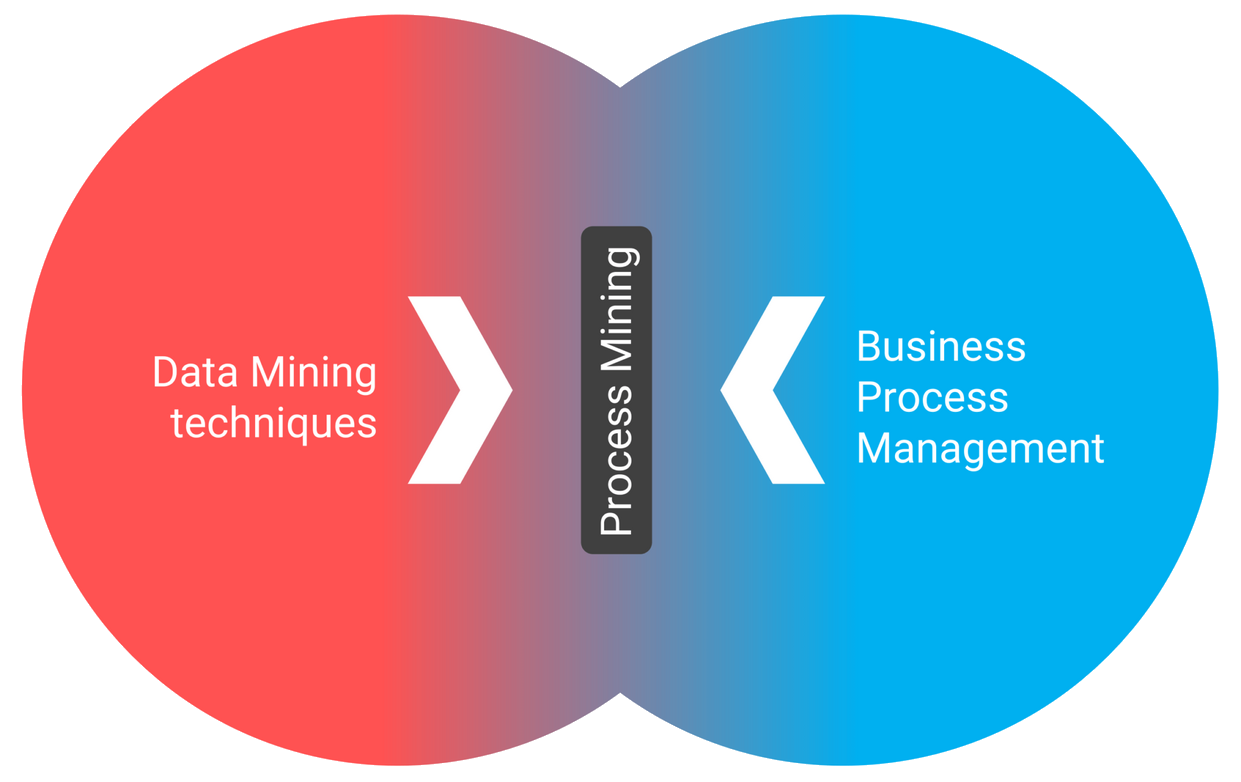 Figure 2: Process mining lies at the intersection of Business Process Management (BPM) and data mining.
Figure 2: Process mining lies at the intersection of Business Process Management (BPM) and data mining.
Now, let’s explore the differences. A substantial distinction and overlap exist between data mining and process mining. A simple example illustrates this difference:
- The focus of data mining is explicitly on patterns within the data. For instance, American Pizza Hut aims to uncover patterns in customer behavior. By using artificial intelligence techniques, the company recommends pizzas based on the current weather and the customer’s location or where they plan to eat their pizza. Certain weather patterns correlate with specific pizza preferences.
- In contrast, the focus of process mining is on identifying anomalies in business processes. For example, why wasn’t the pizza delivered on time, and how can variations in baking times be explained? Process mining uses tools such as event logs, audit trails, and timestamps to address these questions.
Another key difference is that data mining traditionally works with static datasets, while process mining now monitors business processes in real time. Additionally, chance plays a significant role in data mining, whereas process mining often involves analyzing a predefined problem. TechTarget explains:
Data mining is more concerned with the “what” – the patterns themselves – while process mining seeks to answer the “why.”
Data mining focuses on finding correlations and patterns, while process mining uncovers causal relationships.
What is text mining and how does it work under the hood?
The field of data mining is significantly more well-known than text mining, also referred to as text analytics.
 Figure 3: The different steps in the text mining process.
Figure 3: The different steps in the text mining process.
According to the first professor of Text mining in the Netherlands, Prof. Jan C. Scholtes, data mining involves analyzing transactional data stored in relational databases. Examples include credit card payments or debit card transactions. Such transactions can be enriched with various characteristics, such as date, location, cardholder’s age, and salary. By combining this data, it becomes possible to identify patterns of interest or behavior.
Text mining, on the other hand, focuses on discovering relevant patterns and attributes by analyzing unstructured information through automated methods. This enables better searches, deeper data analysis, and faster uncovering of insights that would often remain invisible to the human eye. In recent years, artificial intelligence has also made it possible to generate text: a field known as generative AI.
The idea of data mining is actually straightforward, but the number of potential pitfalls is significant. It involves the interplay of four key areas: people, organization, technology, and data. In each of these areas, you will encounter both small and large challenges to overcome.
The data mining process
When designing your data mining process or creating a data mining process diagram, it’s hard to ignore the widely accepted CRISP-DM standard. Since the late 1990s, this has been the de facto framework for data mining.
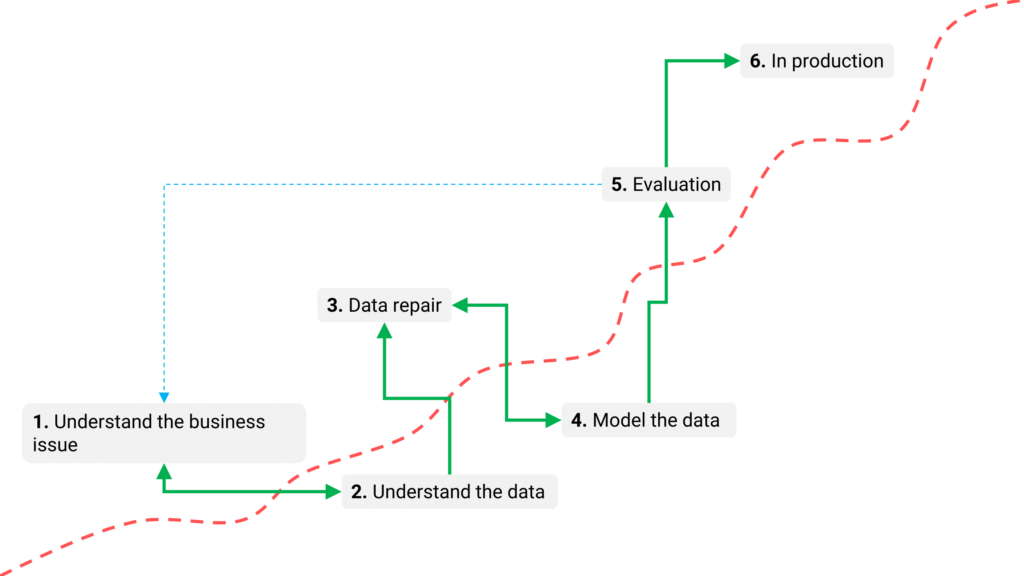 Figure 4: The Cross-industry standard process for data mining (CRISP-DM).
Figure 4: The Cross-industry standard process for data mining (CRISP-DM).
The CRISP-DM protocol is not based on theoretical or purely technical principles but is rooted in real-world practices. It was developed as a practical guide rather than an academic concept, detailing six clear steps for effectively implementing data mining projects.
- Understand the business question: In this first step, you define the objectives of the data mining project and translate the requirements from a business perspective. The outcome is a problem statement and an initial action plan aimed at achieving the goals. At this stage, the business consultant plays a critical role.
- Understand the data: This step focuses on gathering and thoroughly exploring the data. Activities include identifying data quality issues, spotting biases, and gaining initial insights. You discover interesting subsets of data and develop hypotheses about hidden information.
- Prepare the data: Using raw data, you create a final dataset to serve as input for the data mining model. This step involves tasks such as selecting tables, records, and attributes, as well as transforming and cleaning the data. These tasks may need to be repeated as necessary. Typically, this step involves both the data analyst and the data engineer.
- Model the data: In this phase, various algorithms are selected and applied to create a data mining model. Parameters are fine-tuned for optimal results during the training phase, where the desired output data is modeled. Often, multiple algorithms can solve the same problem, but some require specific data formats. This may necessitate revisiting the data preparation stage. The data scientist is responsible for building the model.
- Evaluate the data mining model: Once the model is complete, it must be validated and evaluated step by step. Does it meet the business goals? Is its performance adequate? Have any critical aspects been overlooked? The evaluation determines whether revisions are needed and how the results should be used.
- Implement the model in production: Implementation is usually carried out by the user, not the data analyst. However, if the analyst handles this phase, it’s essential for the user to understand how to use the model effectively. Depending on the requirements, implementation can range from generating a customer report, such as predicting contract renewals, to integrating a repeatable data mining process into a business workflow.
Implementation does not mark the end of the project. Even if the model’s purpose is purely to enhance knowledge, the insights must be organized and shared in a way that colleagues can use. More often, “live” models are integrated into decision-making processes, such as personalizing web pages in real time or continuously scoring new leads in a marketing database. One thing is clear: with a well-designed and properly maintained data warehouse, you can realize the benefits of data mining much faster.
9 data mining examples
 Practical use cases for data mining have been around since the 1990s. However, organizations are often hesitant to showcase them publicly due to competitive sensitivities. One of the most iconic examples comes from the movie classic Moneyball, where data mining revolutionized the traditional world of baseball. Beyond this, many classic business and government applications of data mining are now well-documented. Below, we summarize some notable examples:
Practical use cases for data mining have been around since the 1990s. However, organizations are often hesitant to showcase them publicly due to competitive sensitivities. One of the most iconic examples comes from the movie classic Moneyball, where data mining revolutionized the traditional world of baseball. Beyond this, many classic business and government applications of data mining are now well-documented. Below, we summarize some notable examples:
- Supermarket chains and online stores use data mining techniques, such as association analysis, to identify consumer patterns – for example, which items are frequently purchased together.
- Data mining is used in agriculture and smart farming to analyze weather patterns, crop growth, and fertilization data.
- Factories utilize data mining to uncover patterns and errors in production processes, helping predict and prevent machine part wear and enabling proactive maintenance.
- Data mining software identifies anomalies in patient behavior, medication usage, claims, and protocol adherence to uncover potential fraud.
- Hospitals use data mining and big data analytics to identify patterns in disease progression and hereditary illnesses, ultimately improving the quality of care in the long term.
- Financial institutions leverage data mining algorithms to spot anomalies in payment behavior and human actions, effectively identifying fraudulent activities.
Capital One: a data mining example in finance
 Data mining has helped many organizations and companies work smarter, and Capital One offers a well-known example. As one of the pioneers in leveraging data mining, Capital One uses sophisticated algorithms at every step, from acquiring new customers to retaining them, optimizing credit card offers, and managing risk. These data-driven strategies have significantly improved their ability to personalize services and reduce fraud. For instance, by analyzing customer behavior patterns, Capital One can tailor credit card offers to individual preferences, ensuring higher engagement and satisfaction. This approach not only boosts business outcomes but also enhances the overall customer experience, making Capital One a leader in data-driven decision-making in the financial industry.
Data mining has helped many organizations and companies work smarter, and Capital One offers a well-known example. As one of the pioneers in leveraging data mining, Capital One uses sophisticated algorithms at every step, from acquiring new customers to retaining them, optimizing credit card offers, and managing risk. These data-driven strategies have significantly improved their ability to personalize services and reduce fraud. For instance, by analyzing customer behavior patterns, Capital One can tailor credit card offers to individual preferences, ensuring higher engagement and satisfaction. This approach not only boosts business outcomes but also enhances the overall customer experience, making Capital One a leader in data-driven decision-making in the financial industry.
- For decades, data mining models have been used to analyze patterns in calling behavior and customer churn, with the goal of improving customer retention.
- Data mining software is used by governments to monitor and analyze benefit distribution patterns and citizens’ tax compliance.
- Governments use data mining tools to uncover patterns in crowd control, traffic management, and crime prevention.
If you’re considering working with personal data or applying advanced data mining models, it’s essential to comply with privacy regulations like the GDPR and local laws such as the CCPA, as well as stay informed about policies like the AI Act. For further reading, see our article on “The 15 trends in Artificial Intelligence, Big Data & BI for 2025“.
 In this comprehensive Artificial Intelligence book – with over 25,000 copies sold – the entire spectrum of data analysis, data mining, and AI is covered. The goal: to make much better decisions and to make your organization smarter. It provides you with a perfect framework to structurally shape and implement the bigger picture (BI, AI & Data Science).
In this comprehensive Artificial Intelligence book – with over 25,000 copies sold – the entire spectrum of data analysis, data mining, and AI is covered. The goal: to make much better decisions and to make your organization smarter. It provides you with a perfect framework to structurally shape and implement the bigger picture (BI, AI & Data Science).
Data mining techniques and tools
 All major enterprise software providers, such as SAP, Oracle, and IBM, offer a range of data mining software tools. Additionally, vendors specializing in Business Intelligence also provide these solutions. For an up-to-date comparison of data mining software vendors, refer to the Business Intelligence & Data Analytics Guide™ 2026, focusing on the Analytics, Artificial Intelligence, and Big Data components.
All major enterprise software providers, such as SAP, Oracle, and IBM, offer a range of data mining software tools. Additionally, vendors specializing in Business Intelligence also provide these solutions. For an up-to-date comparison of data mining software vendors, refer to the Business Intelligence & Data Analytics Guide™ 2026, focusing on the Analytics, Artificial Intelligence, and Big Data components.
That said, you don’t always need to spend money to get started. Open-source programming languages such as Python, R, Java, Scala, Julia, RapidMiner, and SAS also offer powerful tools for data mining. Some vendors focus on specific areas like text mining or data mining techniques such as classification, clustering, regression, association, and outlier detection. Regardless of the approach, the core goal of data mining software is recognizing patterns in datasets.
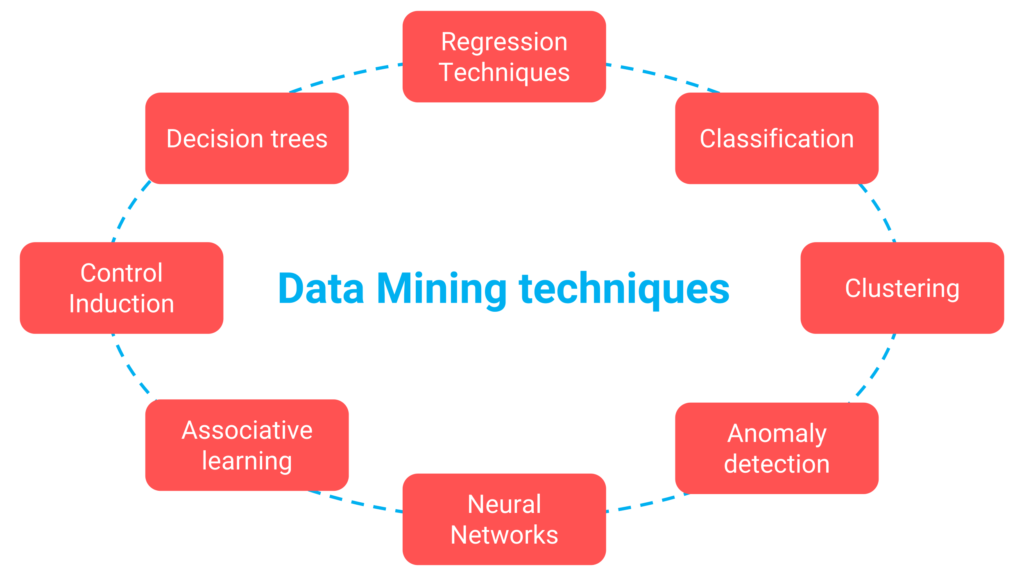 Figure 5: Different techniques that data mining software tools should support.
Figure 5: Different techniques that data mining software tools should support.
According to software vendors, data mining tools are becoming increasingly user-friendly. Many claim that even users without programming experience can achieve impressive results through features like “no-code” or “low-code” environments and drag-and-drop functionality. Some data mining software also specialize in specific sectors, such as agriculture, industry, or education. This specialized market knowledge can be invaluable in quickly addressing the specific business challenges you aim to solve with data mining tool.
The five rules for selecting data mining software
 Providers of data mining software often use exotic terms like “predictive data mining software” or “data mining predictive analytics” to broaden their appeal and increase market visibility. However, the lack of clear definitions in product and service portfolios can make the data mining market less transparent, hinder meaningful discussions, and complicate the process of selecting the right vendors and tools. Clear definitions are essential for choosing the right vendor and data mining tool to address your specific business challenges. Following these five rules can help you avoid missteps or poor investments:
Providers of data mining software often use exotic terms like “predictive data mining software” or “data mining predictive analytics” to broaden their appeal and increase market visibility. However, the lack of clear definitions in product and service portfolios can make the data mining market less transparent, hinder meaningful discussions, and complicate the process of selecting the right vendors and tools. Clear definitions are essential for choosing the right vendor and data mining tool to address your specific business challenges. Following these five rules can help you avoid missteps or poor investments:
- Don’t fall for sales tricks: Software vendors often offer basic and premium versions, with key functionalities like text mining only available in the premium version. Be aware of such limitations before making a decision.
- Use your bargaining power: Vendors are almost always willing to negotiate, especially for bulk license purchases. Keep in mind that so-called “street prices” are typically lower than official list or brochure prices.
- Be critical of license needs: Additional modules, features, or functionalities often come with extra costs. Not every user requires full access to all plug-ins or functionalities, so evaluate your needs carefully to save on license costs.
- Beware of free versions: Some providers offer free versions of data mining software, which might seem appealing initially. However, these often operate on a subscription model that requires costly upgrades to premium versions.
- Maximize your investment: Good documentation is crucial, but it’s not always available with free versions of data mining software. Data mining isn’t something you can master just by reading – hands-on experience is vital. Consider taking a supportive training course.
Hiring a data mining consultant
Bringing in an experienced data mining consultant for your first or second project can be a smart decision. These professionals often work on diverse projects across various industries, allowing you to benefit from a wealth of knowledge and practical experience.
 Figure 6: A good data mining consultant brings experience with use cases from various industries.
Figure 6: A good data mining consultant brings experience with use cases from various industries.
Unlike data scientists, who possess deep technical expertise, data mining consultants have a more balanced mix of skills and knowledge. Their expertise spans organizational science, business administration, process management, IT, and machine learning, making them invaluable for bridging the gap between technical implementation and business needs.
Make data mining a success: 6 tips
 Many data mining projects fail to reach production, which is a significant missed opportunity. Surprisingly, the issues are often not related to technology but rather to organizational or communication shortcomings. For instance, the organizational aspects may be overlooked, user communication neglected, or the project may be entirely technology-driven. Unrealistic expectations from management about the technology often exacerbate these problems. To maximize your chances of success, keep the following advice in mind:
Many data mining projects fail to reach production, which is a significant missed opportunity. Surprisingly, the issues are often not related to technology but rather to organizational or communication shortcomings. For instance, the organizational aspects may be overlooked, user communication neglected, or the project may be entirely technology-driven. Unrealistic expectations from management about the technology often exacerbate these problems. To maximize your chances of success, keep the following advice in mind:
- Apply the CRISP-DM model and follow its six steps
- Pay close attention to data quality, as it can make or break the project
- Build a multidisciplinary team with representatives from both business and IT
- Ensure the team has sufficient knowledge and experience with data mining
- Gather as much relevant data as possible, not just internal data
- Choose the right algorithm for the specific problem or issue at hand
Would you like a detailed explanation of these tips? Feel free to contact us for more information.
Learn more about data mining
 We’ve only scratched the surface of the fascinating field of data mining. Would you like to explore it further? Dive into the details and uncover more by reading the following resources:
We’ve only scratched the surface of the fascinating field of data mining. Would you like to explore it further? Dive into the details and uncover more by reading the following resources:
By expanding your knowledge of data mining, you significantly reduce the risk of project failure. Contact a data mining professional.
Want to get started with data mining, too?
Are you looking for more information about hiring one or more data mining consultants? Our team of independent consultants and experienced instructors is ready to assist you. Feel free to reach out, and we’ll be happy to help you take the next step forward.
About Passionned Group
![]() Passionned Group is a professional consultancy specializing in data mining, AI, and data science. We assist organizations of all sizes with their digital transformation journey toward becoming intelligent, data-driven enterprises. Every two years, we proudly present the Dutch BI & Data Science Award™ to the smartest organization in the Netherlands.
Passionned Group is a professional consultancy specializing in data mining, AI, and data science. We assist organizations of all sizes with their digital transformation journey toward becoming intelligent, data-driven enterprises. Every two years, we proudly present the Dutch BI & Data Science Award™ to the smartest organization in the Netherlands.
Frequently Asked Questions
How do I identify biases in my data?
Detecting biases in data is complex, as many factors may contribute to them. These include data entry processes, workflow design, selection criteria, KPIs that create unintended incentives, and data modeling methods. We recommend having a data mining expert conduct an in-depth study. However, there are steps you can take yourself: talk to the people responsible for data entry, observe their processes, and perform a process analysis.
How is data mining used in healthcare?
It is used to uncover patterns and insights that improve patient care and operational efficiency. Examples include identifying disease trends, predicting patient outcomes, detecting healthcare fraud, and personalizing treatment plans. Hospitals also use data mining to optimize resource allocation and reduce costs while enhancing service quality.
What are the pros and cons of data mining?
Data mining helps uncover hidden patterns, improve decisions, and optimize processes. However, it can be costly, may raise privacy concerns, and relies on accurate data to avoid misleading results.
What problems can data mining solve?
It can solve problems like fraud detection, customer segmentation, predictive maintenance, and optimizing marketing strategies. It also uncovers inefficiencies and trends in business operations.
Can data mining predict?
Yes, data mining can be used not only to classify (e.g., identifying a red car) and cluster (e.g., grouping all red-colored cars) but also to make predictions. For instance, it can predict the likelihood of a customer purchasing a red car or renewing a lease.
What do data miners do?
Data mining analysts or specialists analyze datasets to find patterns and trends. They clean data, apply algorithms, build models, and work with teams to turn insights into actions.
What is an example of data mining in banking?
Banks use data mining to detect fraud by identifying unusual transaction patterns. It’s also applied for credit scoring, customer segmentation, and churn prediction. See other examples here.
What is the difference between data analytics and data mining?
Data mining is a subset of data analytics. Data analytics is a broad term for analyzing data, while data mining focuses on finding hidden patterns and relationships in large datasets.
Is data mining completely different from artificial intelligence?
Not entirely. These two techniques are very similar and often use the same algorithms and models to perform automated analysis. However, AI is broader in scope and can analyze texts, images, videos, and audio. Data mining typically focuses on structured data, while text mining is used for unstructured data, such as textual information.
What is the primary goal of data mining?
The main goal is to discover patterns and insights in data that lead to better decisions, optimized processes, and innovative solutions. Figure 1 illustrates what is the goal and what is needed to reach it.
How much data do you need for data mining?
You can extract meaningful patterns and insights from even small datasets (fewer than 1,000 rows and a few columns), as long as the results are statistically significant. However, larger datasets (more than 10,000 rows and many columns) are necessary for uncovering deeper, more sophisticated knowledge. For example, a small dataset can generate a simple decision tree, whereas a larger dataset allows for a more comprehensive tree, which provides greater insights and value.




