
Build your own machine learning model and discover hidden patterns
Machine learning is fully in the spotlight. That is the case because the improvement potential of machine learning applications for organizations is great. At the same time, the explainability of machine learning algorithms in the private and public domain is under discussion. For years, BI managers used dashboards, reports, and data analytics to uncover the large and relatively simple connections within organizations. Machine learning models, in addition to those big connections, are now uncovering the smaller, more subtle, more complex patterns. But what is machine learning in essence? And how do you build a reliable and working machine learning model? This process is labor intensive, challenging, and time-consuming. Passionned Group recommends the right machine learning tools, implements them, provides a customized Machine Learning course, and delivers interim support.
What is machine learning?
After analyzing different machine learning definitions, we formulated our own conclusive definition, which is simultaneously our main takeaway from this page:
Machine learning is a collection of self-learning algorithms that are able to independently discover patterns based on structured and unstructured data and make reliable predictions that support organizations’ decisions.
In this article, we provide a clear machine learning explanation, a practical machine learning definition, an overview of the available machine learning models and applications, the most important machine learning trends, and last but not least, suggestions for the most suitable basic course in Machine Learning as a stepping stone to a masters in Data Science & Machine Learning.
Self-learning Machine Learning Algorithms
By now machine learning has become a common collective term, an umbrella term for so-called self-learning algorithms. But what are (learning) algorithms anyway? What is the link between business intelligence and machine learning? What is the difference between AI and machine learning?
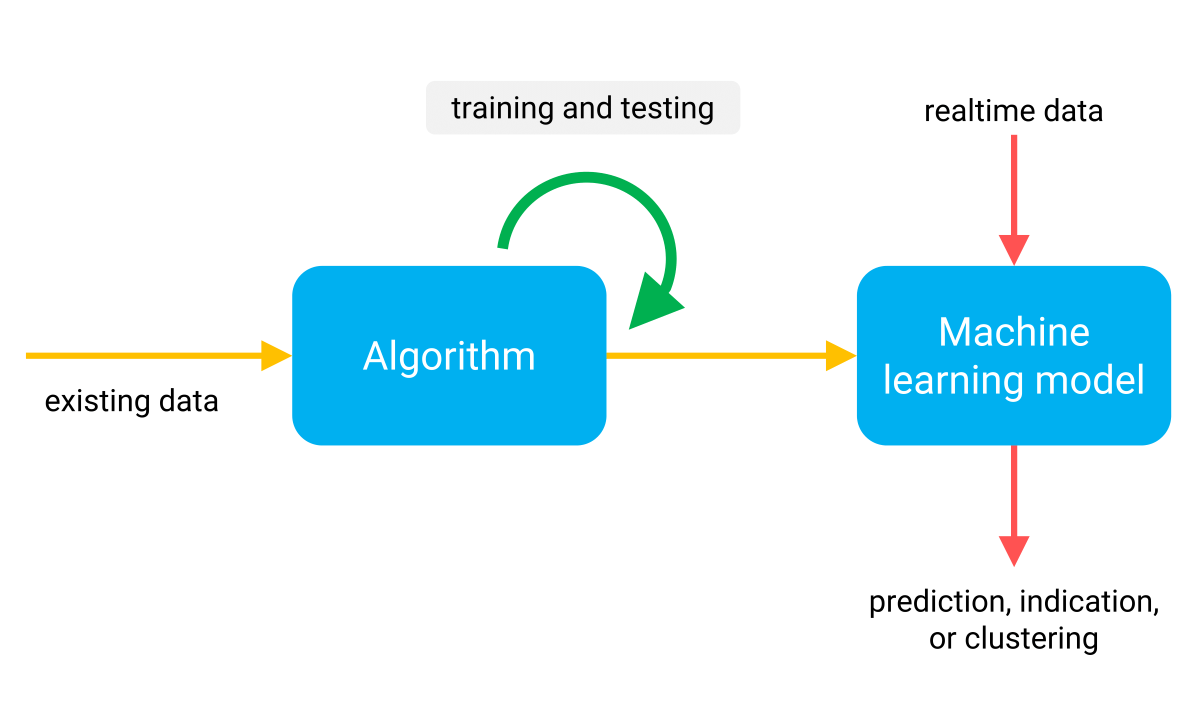 Figure 1: Machine learning models are created by training them with algorithms. These are self-learning computer programs that preserve the optimal end result in a machine learning model.
Figure 1: Machine learning models are created by training them with algorithms. These are self-learning computer programs that preserve the optimal end result in a machine learning model.
Machine learning is booming because companies and institutions have access to more and more machine learning data. Therefore, to understand this digital society dominated by big data and machine learning, an overview of some clear machine learning definitions is indispensable here.
Some machine learning definitions
Machine learning was originally defined in the 1950s as “a field that lets computer algorithms learn without having to explicitly program them” (Samuel, 1959). Another common definition is the following: “Machine Learning is the study of computer algorithms that allow computer programs to improve automatically through experience.” (Mitchell, 1997).
Both machine learning definitions may sound somewhat outdated and static to the ears, but in essence, they do justice to the self-learning nature that is so characteristic of both older and certainly modern advanced algorithms. Algorithms change and are able to develop themselves continuously. In fact, machine learning is a dynamic learning process: the algorithms learn by recognizing patterns in the data.
According to one of the largest software companies in the world, machine learning (ML) is a form of artificial intelligence (AI) aimed at building systems that can learn from processed data or use data to perform better. This definition is practical, dynamic, performance-oriented, and also emphasizes the learning nature, only lacking the predictive capabilities of algorithms.
Big data, data science, machine learning, and deep learning are often mentioned together. The same goes for data analytics and machine learning. However, lumping all these terms together, without specifying the differences and/or similarities between AI, data science, machine learning, and BI, quickly creates confusion.
Let the definitions sink in, but in the meantime remember this sequence from machine learning data scientist David Robinson (2017): data science delivers insights, machine learning delivers predictions, and artificial intelligence delivers guidelines for autonomous actions.
3 different types of machine learning models
Machine learning models can be classified into three different categories on the basis of the learning process that self-learning algorithms go through. Machine learning thus has three main categories.
Supervised learning
Supervised learning occurs when the algorithm learns under the supervision of a teacher or expert. The teacher labels or tags the input data and tells the algorithm which target variable to look for. They give away the correct answer in advance.
In a classification of vacation photos, for example, the supervisor indicates which photos contain a church and which photos do not contain a church. Slowly, the algorithm starts to recognize the photos with churches. You keep this up until you feel that the algorithm has been sufficiently trained and achieves high scores. You then pour this knowledge into a machine learning model after which the algorithm can start assessing new photos, whether or not in real time.
 Figure 2: A schematic representation of a supervised learning process to recognize fruit.
Figure 2: A schematic representation of a supervised learning process to recognize fruit.
Unsupervised learning
In unsupervised learning the algorithm receives a set of data and, without supervision (i.e. without a teacher or expert), looks for associations, categories, and clusters. You do not give it a target variable. The algorithm automatically tries to find structure in the data set and can extract features, for example in which neighborhood a house is located.
The outcomes of this category of machine learning models can be less predictable (there is no right answer) than with supervised learning. Therefore, the success of this type of algorithm is also often difficult to measure. Nevertheless, the next breakthrough in machine learning is expected to come from this angle.
 Figure 3: Unsupervised learning looks for clusters or patterns by itself. All you have to do is offer the data.
Figure 3: Unsupervised learning looks for clusters or patterns by itself. All you have to do is offer the data.
Reinforcement learning
In this form of machine learning you stimulate the creativity of a so-called “agent”, which consists of an algorithm or set of algorithms that each separately perform specific tasks, or as a whole have been given a task. The agent is given only the rules of the game by the designer. Through clever trial-and-error actions (learning from mistakes), the agent seeks a way to a solution within the data machine learning mountain. After all, there are more roads that lead to Rome.
When a piece of the right road is taken, the algorithm gets a “reward”, when taking an unfavorable turn it gets “punishment”. This form of machine learning is now widely used in self-driving cars that must find the optimum in each specific situation between speed, safety, and driving comfort. But also in controlling the arms and legs of a robot.
In addition to supervised and unsupervised learning, there is also a hybrid intermediate form: semi-supervised learning. This type of learning combines supervised and unsupervised learning. Do you also want to work with (un)supervised learning models or reinforcement learning? Then contact us here.
 Figure 4: With reinforcement learning, you combine in one environment the data, a machine learning model, decision-making and actions. With this, you design and build a complete, self-learning, and powerful feedback loop.
Figure 4: With reinforcement learning, you combine in one environment the data, a machine learning model, decision-making and actions. With this, you design and build a complete, self-learning, and powerful feedback loop.
Key features of machine learning models
Machine learning models can be recognized by a number of common characteristics. The most important characteristics are summarized here:
- there is a larger collection of data with many different characteristics or big data
- the discovery of complex connections and patterns that are often not visible to a human being (at a glance)
- the problem definition is predetermined, but the data needed for the problem is not
- sometimes the target variable is known (supervised) and sometimes not (unsupervised)
- good machine learning models are computation and knowledge-intensive
Difference between deep learning and machine learning
Deep learning is a subcategory of machine learning models. Deep learning attempts to mimic the workings of the human brain. The term “deep” refers to the number of layers in the neural network, or depth of the neural network. Artificial neural networks are thus complementary to and inspired by the biological neural networks within the human brain.
The applications of deep learning are diverse. They are successfully used in areas such as image and speech recognition, in translation tasks, or in the assessment of medical scans. For example, a deep learning algorithm is able to recognize different forms of dementia early.
10 popular machine learning applications
You can deploy a machine learning model to support and improve critical business decisions in marketing, operations, HR, finance, and sales. Also, machine learning applications are used in general to improve customer relationships, predict purchasing patterns, reduce waiting times, or to improve social processes in the public domain. Below we illustrate five concrete applications of machine learning in business situations and five examples of machine learning in the public domain.

- Recommendations. The algorithm that recommends movies on Netflix, or products on Amazon, friend suggestions on Facebook, and contact suggestions on LinkedIn is well-known. But web shops also make intensive use of machine learning for product personalization, contextual search results, chatbots, virtual assistants, and artificially generated photo models.
- Irregularity detection. In this form of machine learning, you’re going to focus on exceptions in the broad sense of the word. For example, you can use irregularity detection to detect fraud or filter spam messages in email boxes. You can then look precisely for statistical irregularities in your data. The so-called outliers.
- Dynamic pricing. With dynamic pricing, machine learning algorithms automatically vary the price. That price depends, among other things, on competitors’ prices, the time of day, week, or month, the demand, and the available supply. Dynamic pricing is widely used in the tourism industry by airlines, hotel rooms, and so on.
- Predictive maintenance. Predictive maintenance is one of the most rational and appealing machine learning applications. It prevents unplanned downtime of expensive machines and installations in industry, in the maritime sector, within the civil engineering sector, the energy sector, the oil and gas sector, and so on. You also save on unnecessary maintenance, because you do it exactly at the right time.
- Process mining. In process mining machine learning, specialized algorithms, such as the exotic-sounding alpha miner, fuzzy miner, heuristics, transition system miners, and genetic algorithms, are applied to data from event logs. The goal is to discover process anomalies and better predict future processes by simulating them with machine learning software. Read more about process mining here.
- Law enforcement. In the public sphere, the police use camera surveillance and machine learning data, such as the data from intelligent cameras and microphones, to detect crimes in real time and to map crime hotspots, and predict where and when crime will occur (predictive policing). Also, consider automatic recognition of drivers with a phone in their hand using deep learning.
- Traffic congestion control. Adaptive signal control is a system for automatically adjusting traffic lights according to traffic density. The technology works on the basis of classical machine learning algorithms. In addition, as part of the smart city concept, several municipalities are experimenting with smart lampposts and pedestrian crossings that light up. The concept is equipped with 5G technology, sensors, charging stations, and lighting scenarios.
- Algorithmic Decisions. All ministries, administrative bodies, and implementing organizations use algorithms and machine learning applications to a greater or lesser extent for their decisions. In fact, some legal regulations can only be implemented with the application of decision rules to data. This is especially true for the implementing bodies that carry out financial regulations, such as the Tax and Customs Administration when it comes to property taxes, real estate valuations, or motor vehicle taxes. But also consider the automatic registration of traffic violations (for example, mobile phone use in the car) and the automatic handling of traffic fines.
- Robotic jurisprudence. Machine learning allows you to search jurisprudence online and discover patterns in it. This may one day be a stepping stone to a robot judge passing sentences completely automatically. Because it is difficult for litigants to gain insight into how the algorithm works, this will remain in the future for the time being. However, experiments are underway in the US with machine learning software that estimates the risk of recidivism when a prisoner or suspect is released on bail.
- Roboticized services. Municipalities are deploying both physical robots and chatbots to improve services to citizens. For example, Robotic Process Automation (RPA) eases the administrative workload of municipal officials, and physical robots in municipal offices show citizens the way. RPA and machine learning are made for each other.
The list is certainly not exhaustive. If you are curious about the possible machine learning data science applications in your sector, or are interested in operating your own machine learning business model, please contact us.
The Artificial Intelligence handbook  Machine learning and algorithms are covered extensively in this all-new edition of the AI book. Learn how these powerful techniques can contribute to a more intelligent and agile organization and how to implement machine learning in order to make faster and better decisions. Over 25,000 copies of this book have already been sold.
Machine learning and algorithms are covered extensively in this all-new edition of the AI book. Learn how these powerful techniques can contribute to a more intelligent and agile organization and how to implement machine learning in order to make faster and better decisions. Over 25,000 copies of this book have already been sold.
How machine learning works: an 8-step plan
Building, implementing, training, testing, fine-tuning, evaluating, and bringing machine learning models, such as a predictive model, into production involves a lot. In the following roadmap, we have summarized the eight most important steps for you. This practical roadmap is based on our data scientists‘ years of experience with clients in various industries.
The step-by-step plan is not set in stone but is more intended as a checklist to ensure that you have not skipped any crucial steps. If you are in doubt about the right approach or have detailed questions, please contact one of our data science specialists directly.
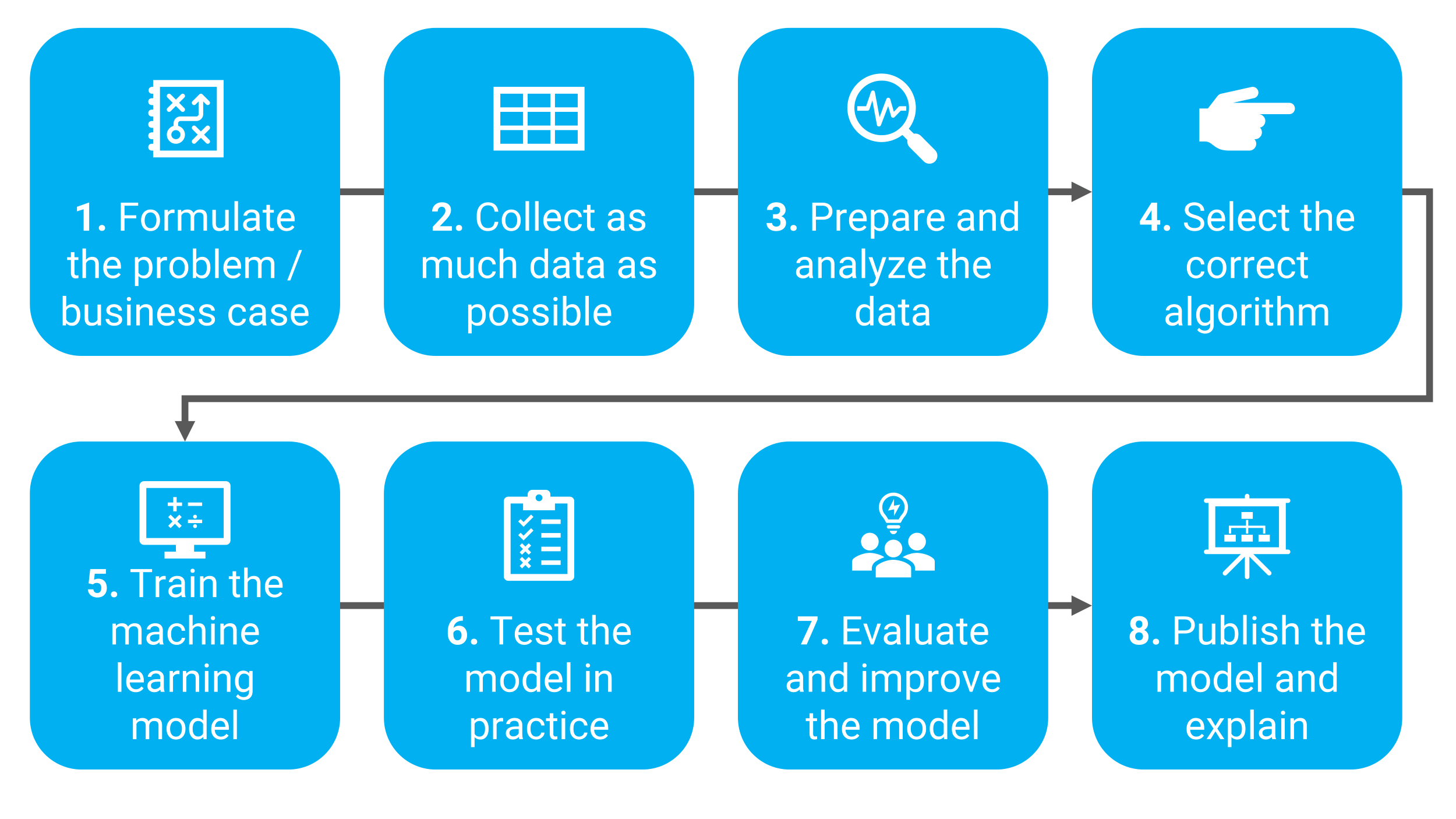 Figure 5: A roadmap for developing machine learning models and putting them into production.
Figure 5: A roadmap for developing machine learning models and putting them into production.
- Formulate a clear problem statement or business case. Preferably do this in the form of a research question, for example: how will the prices of computer chips develop in the next two years? And what explanatory variables play a role in this? Another example: how quickly does a (cold) virus spread across certain parts of the world? Or how can a real estate company predict and plan the necessary maintenance of houses?
- Collect as much historical data as possible on the research question. Do not limit yourself to the internal company data, but also involve external data suppliers in the data collection, such as the CBS, the Chambers of Commerce, sector organizations, and so on. Consult as many different internal and external sources as possible to build up a data collection that is as representative as possible. Ask yourself what data you might still be missing. In this way, you can avoid biases in the machine learning model at this crucial stage.
- Prepare your data and make it suitable for model-based application. Before you can use the collected data for machine learning you will need to transform the raw data into training data (data modeling). Data and files are listed in different formats and extensions. Furthermore, there is usually a lot of data integrity, consistency, and logic to be considered. To get the collected data on the same level, a processing step (data cleaning) is necessary. This is how you transform the raw data into training data.
- Choose the right algorithm. Choosing and optimizing the right algorithm or an ensemble of algorithms for your research question or business case is difficult, especially for laymen. Algorithms are classified into different categories, also called families, such as recommendation systems, classification systems, clustering, anomaly detection, regression models, and text analysis. Each algorithm is designed to solve a different type of research question. Still, it can pay to have different types of algorithms compete with each other to ultimately achieve optimal prediction results through trial and error.
- Train the machine learning model. Thanks to the cleanup of the raw data, you can now get to work with your training data. A common way to train models is to use a training script. During this training process, an algorithm is presented with the training data and independently searches for a way to arrive at a correct answer or solution. In other words, there is an input-output model.
- Test the machine learning model in practice. To ensure that the machine learning model predicts correctly, it must be tested. A second split test dataset is therefore used to check the operation and accuracy of the model: how accurately can the model predict the outcome? There can be both overfitting and underfitting, which means the model predicts outcomes less accurately than expected. Don’t accept a bad outcome.
- Evaluate and improve the machine learning model. After calculating the accuracy, this step allows you to make further improvements to the model. In doing so, use proven statistical techniques such as cross-validation (K-fold cross-validation) to evaluate the performance of the algorithms. In doing so, you split the training data into a number of subsets of the total data sets. You then use these subsets (“folds”) to train the model and you validate with the remaining folds. You repeat this a number of times (K-fold). Finally, you are going to test the performance of your machine learning model and compare it to the final test data.
- Publish the machine learning model and explain it. After you have trained, tested, evaluated, and improved your machine learning model, it is time to roll it out to an acceptance and production environment. Only then will you experience honor from your work. When doing this, don’t forget to explain how the algorithm was (globally) created. For many non-mathematically trained colleagues, a machine learning model is probably a black box that they will greet with some suspicion.
Learn about machine learning with AutoML
The most striking development in the field of machine learning tools is the rise of Auto ML. Besides Google, Microsoft also offers this machine learning tool from its cloud via the Microsoft Azure Platform. In addition, there are several larger and smaller software vendors active in the market that offer platforms and machine learning tools for AutoML.
Overfitting and underfitting of machine learning models
The proper tuning of machine learning models is quite precise. There can be both overfitting and underfitting. Both phenomena cause the machine learning model to perform sub-optimally and not produce the desired reliable predictions.
 Figure 6: Overfitting and underfitting illustrated for regression and classification models.
Figure 6: Overfitting and underfitting illustrated for regression and classification models.
When overfitting and underfitting occur, the machine learning model is perfectly capable of making a correct and even highly accurate prediction or classification based on the training dataset. However, when it is unleashed on a test dataset or actual data, it completely fails:
- Overfitting. The algorithm learned to see correlations based on the training dataset, but in new data, they are not there at all. This indicates overfitting or overtraining. The model was made to be too specific. It contains too many parameters and therefore cannot generalize well or deviate from previously found patterns. The model “remembers” the training data, for example when there are as many parameters as observations, rather than having learned to generalize. One way to avoid overfitting is to feed and train the algorithm with more (diverse) data.
- Underfitting. In underfitting, the machine learning model is too generalistic. It contains too little diversity and cannot specify well. In overfitting, you can still get a handle on this by manually eliminating parameters. In case of underfitting, you could extend the training period of the algorithm.
 Figure 7: Somewhere in the middle is a “sweet spot” where the outcomes of the machine learning model are most reliable.
Figure 7: Somewhere in the middle is a “sweet spot” where the outcomes of the machine learning model are most reliable.
Would you like help optimizing your machine learning model? Then contact one of the machine learning experts at Passionned Group.
Machine learning trends 2026
In addition to the AutoML megatrend mentioned above, we have collected the following machine learning trends for you. We will only touch on them briefly here. If you have any questions or would like more information about our Machine Learning training, please contact us now.

- Calls for legislation and regulation such as the creation of a National Algorithm Registry to enable effective comparison and assessment of machine learning initiatives and algorithms will grow louder.
- More and more voices will be raised to introduce a seal of approval for algorithms, or even more extreme, a so-called “data kill” button. This is with a view to the desired transparency of machine learning and explainability of algorithms.
- The government will try to stop the so-called brain drain of machine learning researchers and experts by improving their (working) conditions.
- With the advance of the Internet of Things and embedded microcontrollers, a new subcategory of machine learning models is emerging: TinyML, which allows you to analyze sensor data on devices with extremely low power consumption.
- So-called Generative Adversarial Networks (GAN systems) produce new content such as, for example, non-existent faces, human voices, texts, news reports, and audio recordings. Governments will try to quell the dark side of GANs, the so-called deep fakes.
Passionned Group, thanks to its extensive network, is able to deliver qualified data scientists on short notice to help you develop and implement machine learning models and applications. Click here to inquire about possibilities and conditions.
Machine learning techniques
Machine learning models use, among other things, different basic techniques (regression machine learning and machine learning clustering) and different types of algorithms. The algorithms range from simple functions, business rules, decision trees, and cluster analysis, to linear regression, logistic regression, so-called probabilistic or Bayesian networks, and genetic algorithms. A complete overview and description of all types and flavors of algorithms can be found in the Artificial Intelligence book.
 Figure 8: The different types of machine learning techniques.
Figure 8: The different types of machine learning techniques.
We can additionally distinguish a number of more generic machine learning techniques such as data mining, text mining, and natural language processing.
- Data mining is a technique for finding connections, patterns, and correlations in structured data using machine learning, statistics, and database techniques.
- Text mining is finding connections, patterns, and correlations in unstructured data such as text. Again, the goal is to gain new insights and knowledge.
- Natural Language Processing is the field that deals with computers reading, understanding, and producing human language.
5 machine learning tips
- As Stephen Covey advised, “Begin with the end in mind”. Always start machine learning with a specific end goal in mind. Machine learning projects have the highest chance of success if you focus on a specific, urgent problem that needs a solution. Focus on a problem with impact on your bottom line. Keep a sharp focus on that end solution. KPIs are the perfect opportunity for this.
- Bring different knowledge domains together to best define and frame the problem to be solved. Developing machine learning models is labor-intensive, challenging, time-consuming, and requires collaboration from experts across disciplines. Start with a simple model and temper expectations if they are too high.
- Because machine learning is already very computationally intensive, you should perform as few additional operations as possible. If you are working with structured data, prepare all the necessary data in one so-called “flat” file. This allows you to train the algorithm faster and come up with results more quickly.
- Don’t try to reinvent the wheel yourself. Software vendors often have already developed the necessary machine learning tools, cheat sheets, and programming languages, such as Python machine learning and machine learning software. Make use of the available platforms, off-the-shelf libraries, and AutoML. So you don’t have to develop the Machine Learning tools yourself.
- Don’t forget to factor in the context of the historical training data. The independent variable you put into a machine learning model may be colored by cultural factors, allowing biases or prejudices to creep into the training data. Discrimination against certain groups is always lurking when defining algorithms.
Hire a freelance machine learning expert
Developing machine learning models is labor intensive and requires the collaboration of experts from different disciplines in the organization. Hiring an external freelance machine learning specialist may be wise to get everyone on the same page. Contact us now if you are considering hiring a data scientist, machine learning expert, or AI consultant.
Master of Data Science
Learn all the ins and outs of machine learning, big data, and data-driven organizations in our 10-day Master of Data Science training course. Take steps towards success in implementing machine learning and data science and enroll today. Passionned Academy’s training responds to the growing need among (business) analysts, aspiring data scientists, and other professionals to start experimenting with AI, data science, machine learning, algorithms, and everything related to it. Contact us to know more.
More information
Technical books on machine learning abound. But if you’re looking for a practical book that explains machine learning models and algorithms in an accessible, understandable way, then The Data Science Book is an absolute must. Order the book now or take our Machine Learning course as a stepping stone to a Master of Science degree in Machine Learning. If you want advice, please contact us.
About Passionned Group
![]() Passionned Group is a leading specialist in Data Science & machine learning solutions. Our experienced and passionate consultants help smaller and larger organizations transform into intelligent, data-driven organizations. Every other year we organize the Dutch BI & Data Science Award.
Passionned Group is a leading specialist in Data Science & machine learning solutions. Our experienced and passionate consultants help smaller and larger organizations transform into intelligent, data-driven organizations. Every other year we organize the Dutch BI & Data Science Award.

