
Make thorough data analyses with a data warehouse
With data warehousing, you build a solid, future-proof data infrastructure that enables simple and complex data analyses, flexible reporting, data mining, and interactive KPI dashboards. Learning processes can be accelerated by a factor of at least 10. A data warehouse is indeed necessary to realize effective and user-friendly Business Intelligence applications. But do you need a data warehouse or can you fall back on (cheaper) alternatives such as a logical data warehouse? First, we explain what a data warehouse is, what the basic principles are, and how to build a data warehouse architecture. We also advise you on how best to build a data warehouse and we do complete implementations.
What is a data warehouse?
 A data warehouse combines data from different sources and applies a specific data modeling (with facts and dimension tables) so users get answers to questions very quickly. Whether it’s an ad hoc analysis, a new report or dashboard that you want to build, or a machine learning model, data warehouses deliver the right data at lightning speed. Here we provide another concise definition of a data warehouse:
A data warehouse combines data from different sources and applies a specific data modeling (with facts and dimension tables) so users get answers to questions very quickly. Whether it’s an ad hoc analysis, a new report or dashboard that you want to build, or a machine learning model, data warehouses deliver the right data at lightning speed. Here we provide another concise definition of a data warehouse:
A data warehouse is an integral database where you can find, combine, and analyze relevant, structured data from different sources arranged by topic.
You are not allowed to change data in a data warehouse database, you can only add (correction) records. This essential principle is one of the things that must ensure that the production of management information is reliable.
Solve complex questions at the speed of light
In a data warehouse (DWH) you mix all your company data but also relevant external data. You will clean up, combine, synchronize, and summarize the data. This allows data analysts and decision-makers to get answers to numerous more complex questions at lightning speed. For example:
- Which customers do you earn the most from, why, and what does the customer journey look like?
- Where are the largest work stocks and longest lead times located?
- In which zip code areas do potential customers for our new product live?
- Which claims are suspicious and how can you make the right selection from them?
- Which department has the highest absenteeism and what is the cause?
- Which customers have payment arrears that are higher than the norm?
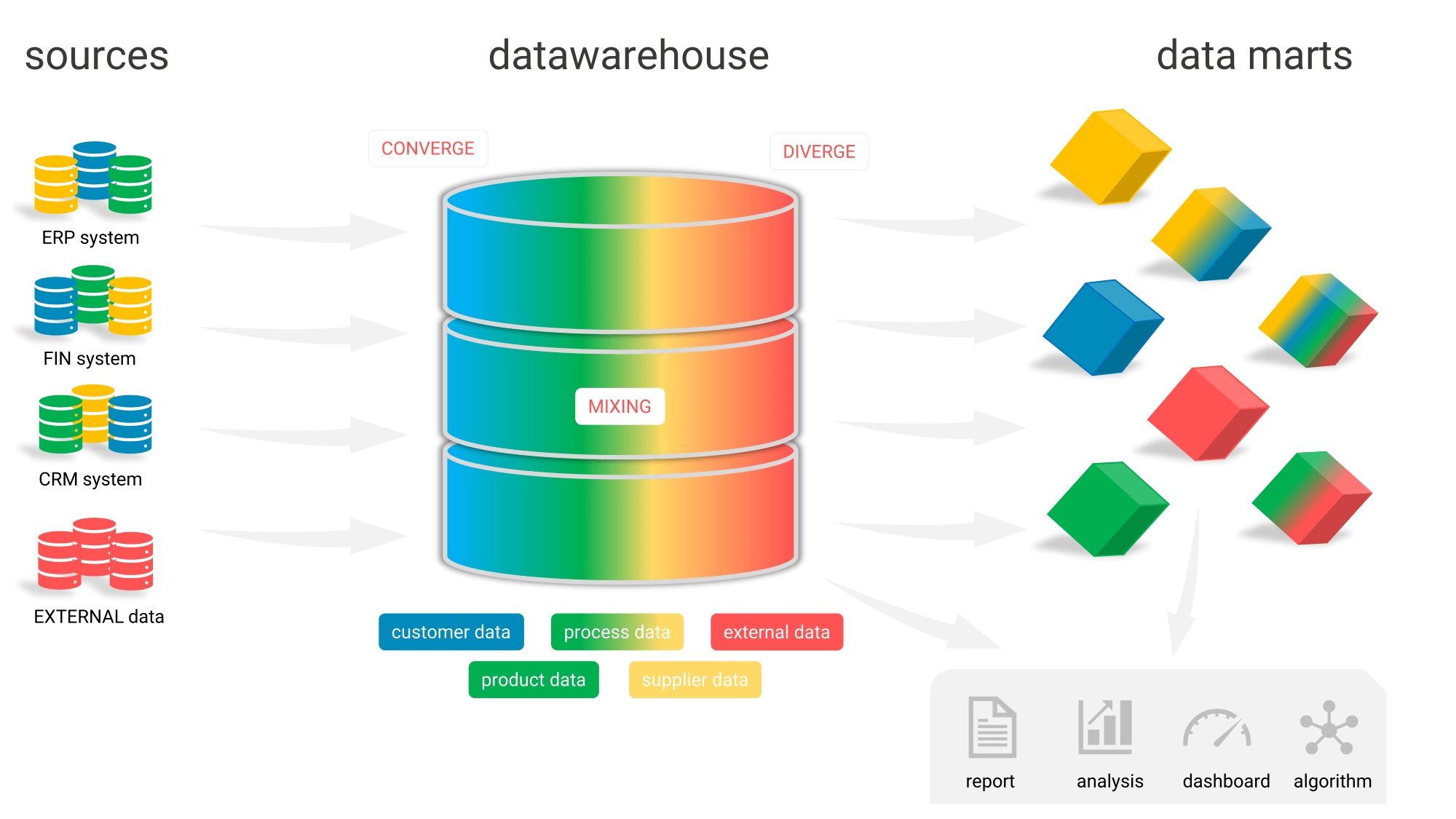 Figure 1: By bringing data together and aligning them in a data warehouse, you can easily build an integrated customer view. And you can quickly analyze the data from multiple angles. Finally, a data warehouse allows your organization to tilt. Are you curious about how that works? Leave a message here.
Figure 1: By bringing data together and aligning them in a data warehouse, you can easily build an integrated customer view. And you can quickly analyze the data from multiple angles. Finally, a data warehouse allows your organization to tilt. Are you curious about how that works? Leave a message here.
The diagram above makes it broadly clear why a data warehouse is so important. Users can make all kinds of cross-connections across departments and systems at the push of a button.
What is a logical data warehouse?
Data in data warehouses is not always physically stored on a hard drive. There is also such a thing as a “logical data warehouse”. In this case, you model the data in accordance with data warehousing principles but you retrieve the data directly from the source via the logical model. With data virtualization software you can neatly arrange this. The disadvantage of this is that you cannot build up a history and your source systems can fall over in the event of more complex analyses or large reports.
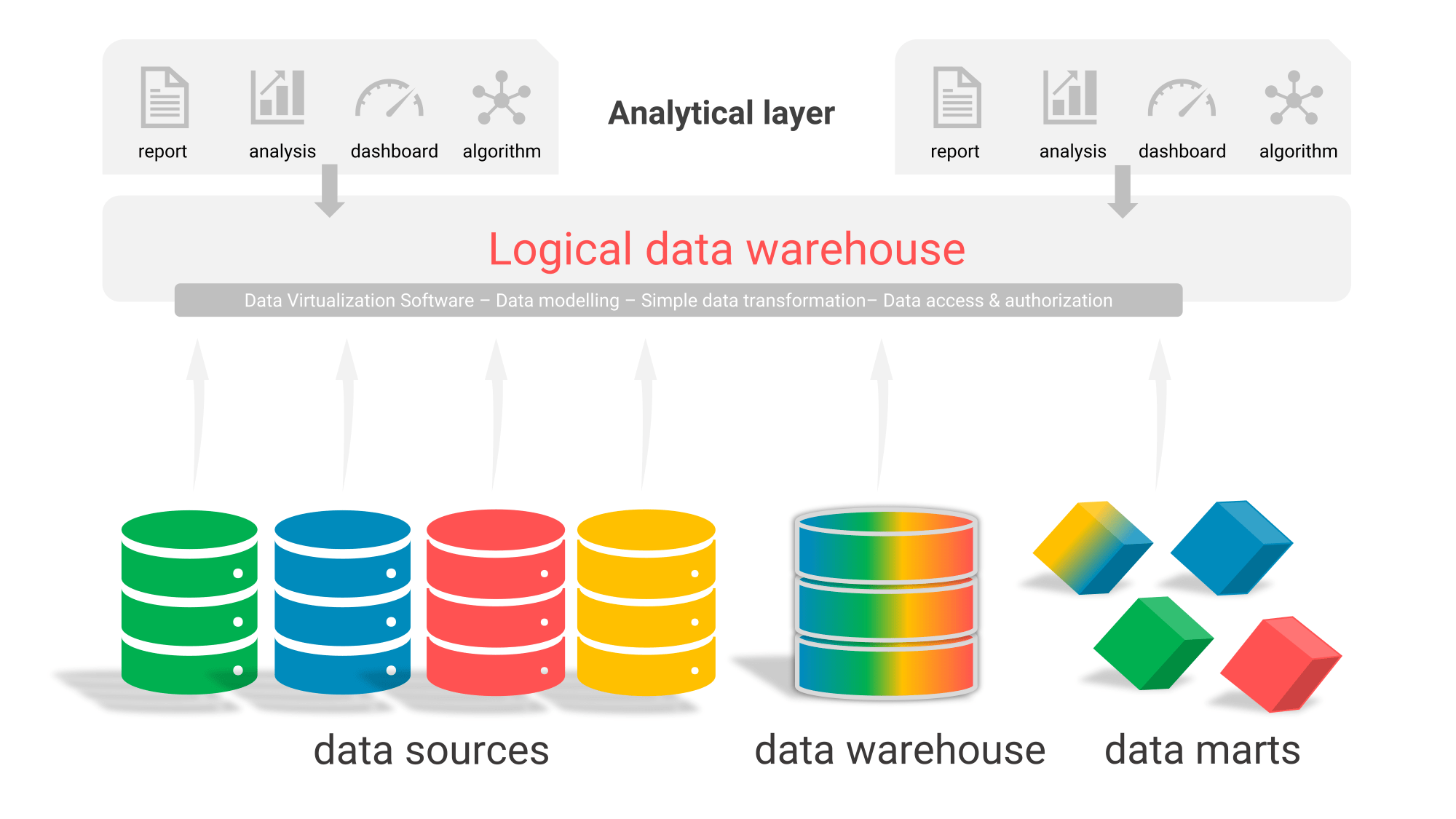 Figure 2: With a logical data warehouse, you don’t have to store all the data in a physical data warehouse.
Figure 2: With a logical data warehouse, you don’t have to store all the data in a physical data warehouse.
In practice, it is often unfeasible to run all reports and dashboards through the line of a full logical data warehouse. Not only can the source systems ‘fall over’, for example, but in a number of cases the figures cannot be calculated accurately enough. Therefore, the hybrid model is currently popular. What is possible goes through a logical data warehouse, what is not possible you store in the physical data warehouse. A logical data warehouse can then combine data from the physical data warehouse, the data marts, and the data sources.
Data warehouse significance grows with the maturity of BI
When you start with Business Intelligence & Analytics, it is not wise to set up a large-scale data warehouse right away. After all, the benefits do not always outweigh the costs. Because better decisions are not the result of a well-designed data warehouse but of decision-makers and analysts who work in a data-driven way and are data-literate. Imagine a data warehouse as a Ferrari, then you also need a Max Verstappen. When you grow in BI maturity, then you also start doing more complex analyses from different angles (marketing, finance, operations, et cetera.). And in that case, you need a more robust data infrastructure, and the added value and meaning of a data warehouse grows.
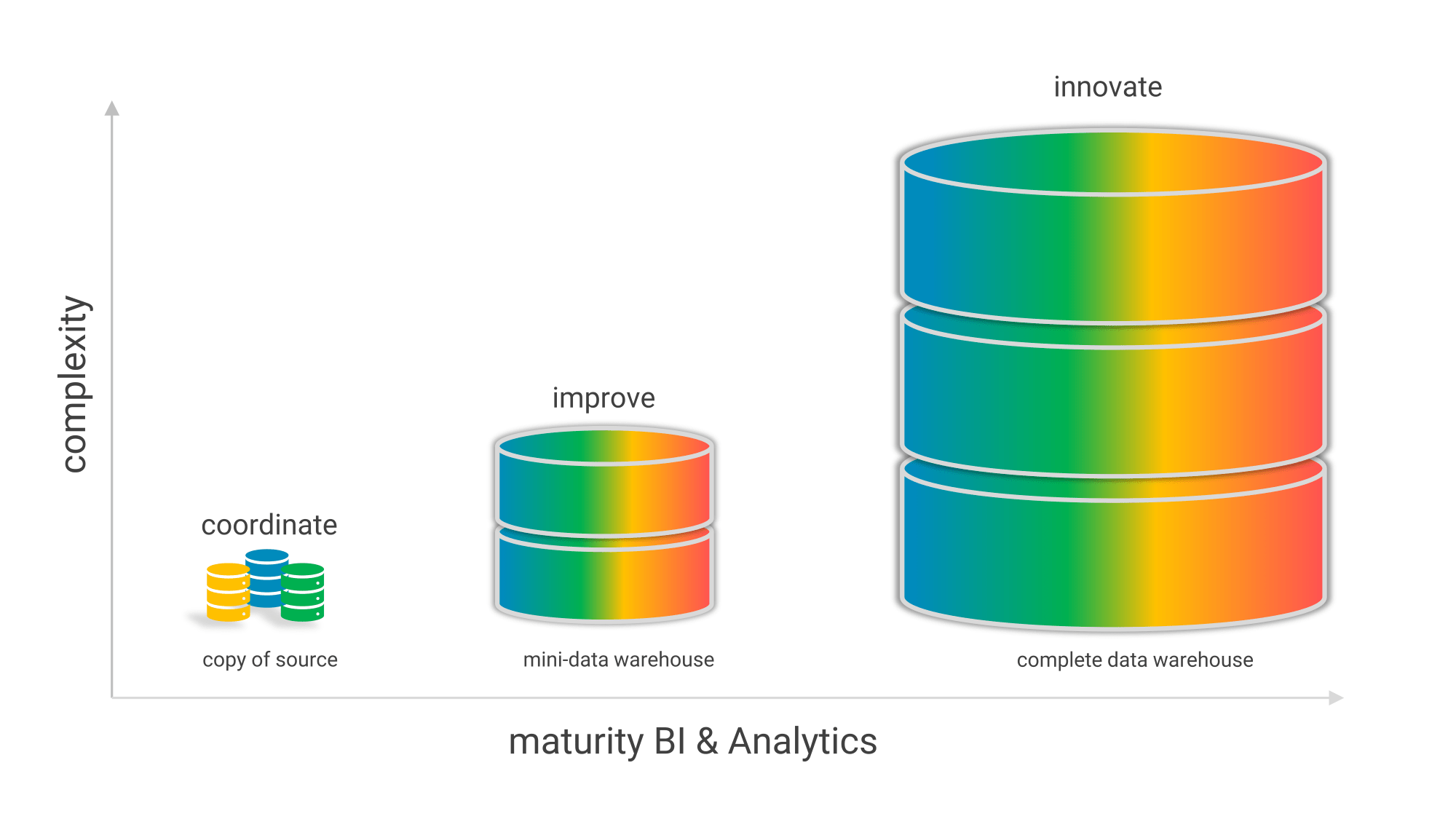 Figure 3: Data warehouse significance, complexity, and size grow with the maturity of Business Intelligence & Analytics.
Figure 3: Data warehouse significance, complexity, and size grow with the maturity of Business Intelligence & Analytics.
How do you go about setting up and using a modern data warehouse?
Setting up a structured, modern data warehouse is a very complex task because there are many design dilemmas to be considered. One of the dominant data warehouse dilemmas involves “storage space versus speed.” An index on a table means extra storage of data, but when you want to look something up, it also means a much faster response time. Because storage space costs hardly any more money and the aspect of speed is still underestimated, the choice is quickly made as far as we are concerned. In a data warehouse architecture, you ensure that the user (report viewer, analyst, data scientist) experiences formidable speed in 80% of the queries. Because learning from data can then take place much more easily. So a modern data warehouse is heavily optimized in terms of speed.
Design a “facts and dimensions” data warehouse
The structure of the data in your sources is unsuitable for (heavy) analysis. You have to link too many tables and search through too many records to get an answer to your question. In your data warehouse, you will therefore use an ETL process to transform the structure of your sources into a dimensional structure with facts and dimensions. This structure is called a star schema that allows the user to select data easily without having to link all kinds of tables. All of this happens automatically under the hood and out of sight of the user. Setting up a modern data warehouse is therefore aimed at achieving an optimal user experience: information must be quickly findable in the data warehouse and the system must respond quickly with correct answers to questions.
Design tips from our data warehousing consultants
As a data warehouse consulting company, Passionned Group has been building data warehouses for over 20 years in various sectors: banks, insurers, municipalities, retailers, hospitals, etc. We always start by drawing up a data warehouse business case. We map out the desired analyses, reports, and dashboards (the most important queries), estimate the costs and benefits, and list the most important advantages. Of course, our data warehouse specialist(s) also look at the data literacy of the (future) users and the maturity level of BI, because that determines how “heavily” you have to rig your data warehouse.
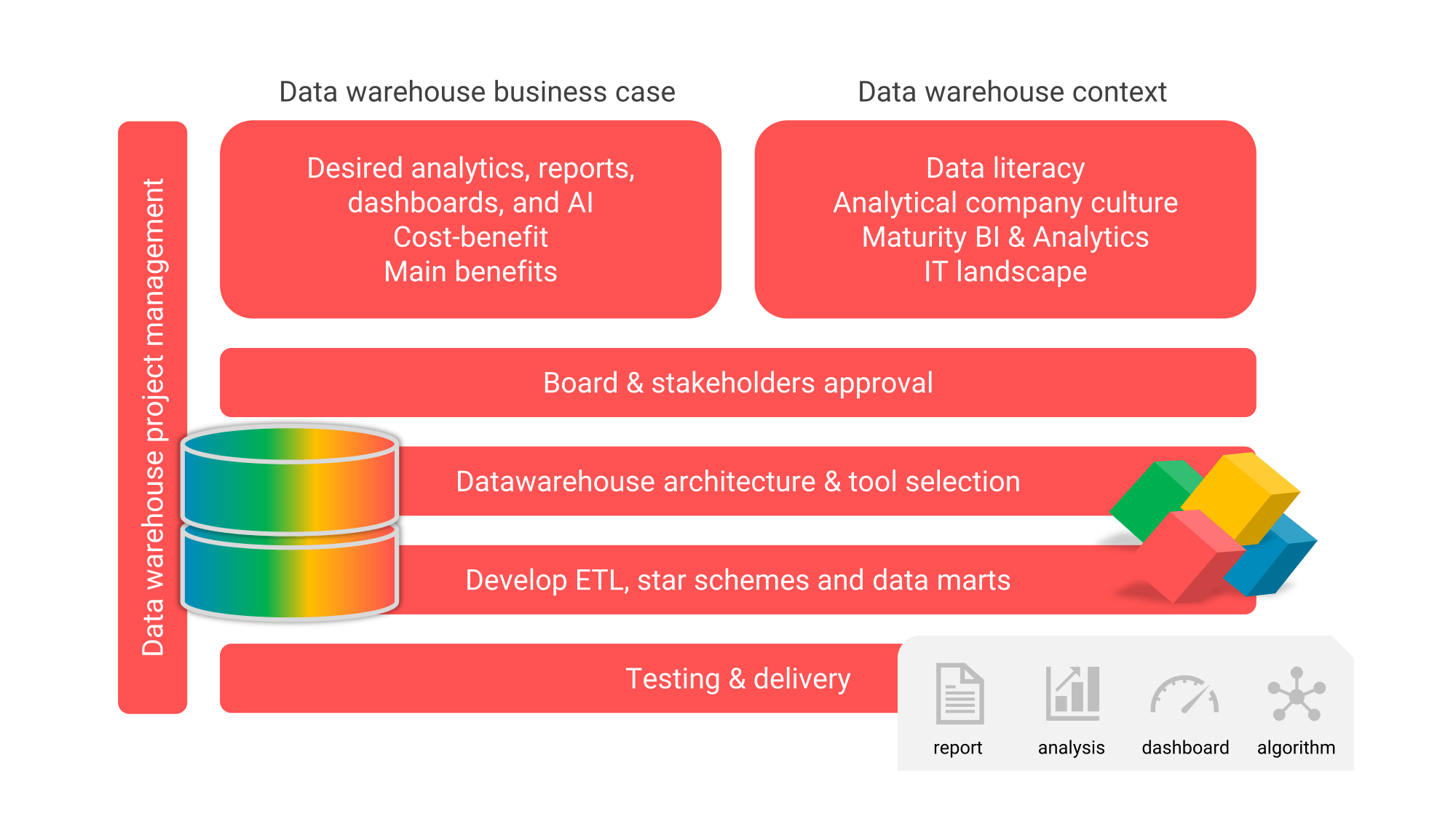 Figure 4: The steps in setting up a data warehouse (request advice).
Figure 4: The steps in setting up a data warehouse (request advice).
After the business case is approved by the stakeholders (including management), our data warehouse architect gets to work drawing out the architecture and designing the data model. Then our data warehouse developer will start building the required ETL, developing the star schemas and data marts. Of course, a deliberate choice will first be made for the required data warehouse software such as the database management system (RDBM), a data warehouse automation tool, and/or an ETL tool.
Our data warehouse experts have several guides that will help you quickly understand the strengths and weaknesses of the required data warehouse tooling. Finally, we can take on the project management for data warehousing and data analytics, preceded by an independent consultation on the most efficient design for the data warehouse.
What is important in data warehouse governance?
Because you bring a lot of internal and external data together in a data warehouse, you need a good governance structure and data warehouse management. In a data warehouse governance model, you apply many principles from the well-known DAMA-DMBOK2 framework. The governance of data in accordance with that framework helps you create new policies, procedures, and standards for data sources, security, definitions, access, and the impact this may have on existing or future business processes. Also, consider master data management (MDM) and data warehouse metadata.
Here is a brief explanation of these concepts:
- Master Data Management (MDM): this discipline brings essential master data into sharp focus and ensures one-time entry. This amounts to storage in one central location. In some specific cases, master data also remains available in designated source systems. In that case, centrally managing a universal set of master data is crucial for proper and efficient business operations.
- Metadata: turns the underlying data into truly useful information. Metadata tells what the data is, where it comes from, how it was produced, what quality the data possesses, et cetera. In combination with MDM, it can work wonders in the correct, timely, and reliable use of data within your organization. Especially if that data is stored in a fragmented way, metadata is indispensable. Something that is becoming increasingly apparent with the rise of Big Data.
Setting up and optimizing the processes around MDM and the management of metadata are the most important items in the toolbox of the management data warehouse.
Master Data Management vs data warehouse
 Many people don’t have a clear understanding of the conceptual framework surrounding data warehousing. They wonder, for example, about “master data management vs data warehouse”. This is comparing apples and oranges because, with a good BI data warehouse, you can easily implement master data management because that’s where a lot of data comes together. Then you can very well determine which data is the “master” over other data. But data warehousing is not the only technology that makes an MDM data warehouse possible. You can also buy separate MDM software that allows you to set up master data management and manage the master data.
Many people don’t have a clear understanding of the conceptual framework surrounding data warehousing. They wonder, for example, about “master data management vs data warehouse”. This is comparing apples and oranges because, with a good BI data warehouse, you can easily implement master data management because that’s where a lot of data comes together. Then you can very well determine which data is the “master” over other data. But data warehousing is not the only technology that makes an MDM data warehouse possible. You can also buy separate MDM software that allows you to set up master data management and manage the master data.
Get rid of the Excel addiction
Numerous best practices show that investing in data warehousing makes an organization more intelligent. And that it can earn you big money in some situations. You do have to get certain preconditions right if you are going to set up a data warehouse. Nevertheless, the use of Excel as a “data warehouse” is still often commonplace.
 Figure 5: Don’t build a data warehouse in Excel, it costs much more money than setting up a good data warehouse once.
Figure 5: Don’t build a data warehouse in Excel, it costs much more money than setting up a good data warehouse once.
The risks are obvious. If your people are addicted to Excel, this naturally encourages mistakes: it is very labor intensive and everyone can use their own version of the truth. Precious time might then be wasted on interpreting and checking data correctness during a meeting, for example, instead of translating the data into analysis and actionable insights to improve the organization.
Not to mention the valuable time that highly skilled employees spend with Excel. They collect and correct the data every time. Excel really stands in the way of effective information use, thorough analysis of the data, and good management of the organization.
With the arrival of a data warehouse, you say goodbye to Excel for good.
Consider alternatives to a data warehouse
 There are certainly useful alternatives for setting up and designing data warehouses. Excel is certainly not a good alternative. But so-called appliances and data virtualization are, to a certain extent.
There are certainly useful alternatives for setting up and designing data warehouses. Excel is certainly not a good alternative. But so-called appliances and data virtualization are, to a certain extent.
- A data warehouse appliance is a combination of hardware, software, and storage. It can process your data very quickly and make it available to users. Given the low maintenance and good performance, an appliance can certainly be useful in a data warehouse environment. Virtually all leading BI tools/platforms can work with these appliances nowadays. Part of an appliance is an in-memory database. This loads all the data into the internal memory of the server. The result? Lightning-fast response times. However, such a “data washing machine” limits your agility. It is largely pre-programmed.
- Data virtualization software decouples data sources from applications and reports. It provides users with a virtual data layer over different data sources. You can then access those in real time; the software will transform, integrate, and deliver the data as it goes. This allows you to present a heterogeneous collection of data sources for all reports as one logical whole. Traditional integration solutions physically integrate the data into a data warehouse. With data virtualization, you get the data delivered integrally on demand. This, of course, increases the speed and flexibility of delivery. However, such a virtual data warehouse must first be properly defined. Moreover, the question is whether your IT landscape is suitable for this. Again, it will not be the preferred approach in all cases.
We know the pros and cons of the various alternatives like no other. Through our years of experience at Passionned Group, we can advise you on the various options.
The Data Science book for Decision Makers & Data Professionals This bestseller contains a complete recipe for building the most efficient data warehouse possible. The author extensively covers the most important goals you want to achieve with a data warehouse. In addition to the theoretical concepts and trends in thinking about data warehouses, this book also contains several case studies. Readers of this beautifully designed book will get a complete and objective picture of the added value of a classic data warehouse. Finally, they will also be provided with alternatives for a data warehouse.
This bestseller contains a complete recipe for building the most efficient data warehouse possible. The author extensively covers the most important goals you want to achieve with a data warehouse. In addition to the theoretical concepts and trends in thinking about data warehouses, this book also contains several case studies. Readers of this beautifully designed book will get a complete and objective picture of the added value of a classic data warehouse. Finally, they will also be provided with alternatives for a data warehouse.
The 15 basic principles of data warehousing
When setting up a data warehouse, you first think about some basic principles. The most important principles are:

- Symmetry: the data warehouse architecture mirrors the business operations or processes. This ensures an overall picture and one version of the truth, so that data warehouse BI seamlessly connects to the information needs and challenges of teams in the organization.
- Mandatory use and mandatory delivery: the data warehouse is a unique, independent, and generically applicable business function and its use is mandatory. Delivery of data to the data warehouse is mandatory, even if a team or department is not yet using it.
- Granularity: the data is delivered as detailed as possible. It has exactly the same granularity as in the source systems. This principle increases the testability and verifiability of the data. It also makes detailed reports and analyses possible because no data evaporates along the way. The latter is the case if you deliver the data in a condensed form.
- Data quality: the data warehouse monitors and controls the data quality but you place the responsibility for data quality with process owners; they actively oversee it.
- Privacy by design: you ensure that personal data can never be stored or used inappropriately or without a proper basis, or can never be made recognizable.
- Different flavors: a data warehouse helps users to create reports, data discovery, ad hoc analyses, downloads, self-service BI, interactive dashboards, develop algorithms, and performance management.
- Synchronization: the refresh rate of the data warehouse precisely matches the regularity and frequency of events in the relevant business processes. As a result, the user cannot miss important events.
- Streaming first: when you use this principle, you are always going to update your data warehouse or data lake (near) in real-time whenever possible.
- Non-volatile data warehouse BI: once data is included in your data warehouse, you may never change it again, even if the data is wrong. However, you may add data that corrects the error.
- Maintainability and extensibility: the logic, calculations, and intelligence in the indicators, metrics, and dimensions are stored in one place. This will greatly improve maintainability and extensibility.
- Complexity under the hood: indicators and dimensions are directly selectable for users to use in reports, dashboards, or interactive analyses. This allows you to create them quickly and easily. It prevents each employee from having to or being able to compile their own indicators. A data warehouse hides the complexity under the hood.
- Flexibility and completeness: when populating the data warehouse, the loading process takes as much meaningful surrounding and adjacent data as possible from the selected data sources. This allows end users and data analysts to more easily create new and meaningful combinations of indicators and dimensions. For example, when one attribute from a table is needed for a report, you include all attributes from that table. This increases the power and expands the capabilities of the analysis function within the organization.
- Independence from specific BI tools: the architecture should be as independent as possible from the software (ETL and BI tools, among others) to be used or purchased.
- One data warehouse database: one data warehouse and big data sources can be accessed via the data lake.
- Cloud-first: all components of your ETL/data warehouse are placed in the cloud (Azure, Amazon, Google Cloud, etc.) unless there are compelling reasons not to do so.
In the early stages of data warehousing business intelligence, you will have to compromise because otherwise the data warehouse will be too expensive or users will drop out because it takes too long to set up. But you should not make concessions to 5 principles: symmetry, mandatory delivery of data, privacy by design, non-volatile, and cloud-first. Do you want to know how this works exactly? Then contact us here.
Speed up your learning processes by a factor of 10
 With a data warehouse, you not only get the answers to more complex questions to the surface quickly but also those to straightforward questions. A super-fast data warehouse can speed up the learning processes of your teams and employees by at least a factor of 10. This enables you to make process improvements and innovations visible to the right people more quickly. And your organization is going to gain a lot in agility. And that in turn will help you with the necessary transition to becoming an intelligent, data-driven organization. Our experienced data architects will be happy to help you further.
With a data warehouse, you not only get the answers to more complex questions to the surface quickly but also those to straightforward questions. A super-fast data warehouse can speed up the learning processes of your teams and employees by at least a factor of 10. This enables you to make process improvements and innovations visible to the right people more quickly. And your organization is going to gain a lot in agility. And that in turn will help you with the necessary transition to becoming an intelligent, data-driven organization. Our experienced data architects will be happy to help you further.
Overview of data warehouse software
If you are going to set up a data warehouse, you will in any case need a data warehouse database to store the data. In some cases, this database also contains built-in tools to fill your DWH, for example, an import function to load CSV files. But in many cases, you will have to look out for data warehousing ETL tools or data warehouse automation software. You can also purchase a so-called data warehouse appliance. This is a special, very fast data warehouse server that, under the hood, automatically does all sorts of things like indexing the data.
The ETL & Data Integration Guide The ETL & Data Integration Guide™ 2022 makes tool selection very easy. This guide will provide you with all the knowledge and resources you need to analyze and assess the ETL vendors (20+ vendors our covered like Informatica, SAP, Microsoft, and so on). In doing so, you’ll automatically drill down to the core of other important data warehouse processes.
The ETL & Data Integration Guide™ 2022 makes tool selection very easy. This guide will provide you with all the knowledge and resources you need to analyze and assess the ETL vendors (20+ vendors our covered like Informatica, SAP, Microsoft, and so on). In doing so, you’ll automatically drill down to the core of other important data warehouse processes.
SAP Business Warehouse (SAP BW)
SAP has its own data warehouse: business warehouse. The advantage of this is that if you use SAP for all processes, you do not need to set up a new data warehouse. You get it as a gift from SAP. Of course, you pay the license fees but the development costs are significantly lower compared to setting up a completely new data warehouse. If you use many other systems besides SAP, the business case for setting up and using SAP BW will not be made quickly. The reason? You can’t just load data from other systems into the business warehouse in a fast and efficient way.
What is an Oracle data warehouse?
 Oracle also delivers a data warehouse that you can buy and use separately. This is the ‘Oracle Autonomous Data Warehouse‘. It contains all the data warehouse software that you need to set up and manage a data warehouse. You can use two ETL tools: Oracle Data Integrator (ODI) and Oracle Warehouse Builder (OWB). Want to know exactly how Oracle data warehouse software scores against other data warehouse tools? Then download the ETL & Data Integration Guide 2025 here.
Oracle also delivers a data warehouse that you can buy and use separately. This is the ‘Oracle Autonomous Data Warehouse‘. It contains all the data warehouse software that you need to set up and manage a data warehouse. You can use two ETL tools: Oracle Data Integrator (ODI) and Oracle Warehouse Builder (OWB). Want to know exactly how Oracle data warehouse software scores against other data warehouse tools? Then download the ETL & Data Integration Guide 2025 here.
What does a complete data warehouse architecture look like?
With the principles in hand and the information needs of the users, you get to work designing a data warehouse architecture. This not only identifies the necessary facilities (capabilities) of the architecture (for example a real-time data warehouse) but also deals with the method of data modeling. You can have long and heated discussions about the latter and there can even be a real tribal war within the team. But before we delve deeper into that, let’s look at the most important components of the ideal data warehouse architecture.
The key components of an enterprise data warehouse architecture
It is important to understand that building a mature and complete data warehouse can take many years and involves large investments for which you develop a solid business case. For example, Ahold took no less than seven years to build a single enterprise data warehouse that everyone in the company could use.
A data warehouse is not an end in itself but a means to make better decisions and to improve and accelerate decision-making at all levels in your organization.
Because the management and all the executives within this company understood very well the value of good data and a data warehouse, the business case was quickly made. But that is the exception rather than the rule. That’s why a data warehouse architecture doesn’t have to be intended for eternity. You work situationally, of course, without losing sight of the long-term perspective:
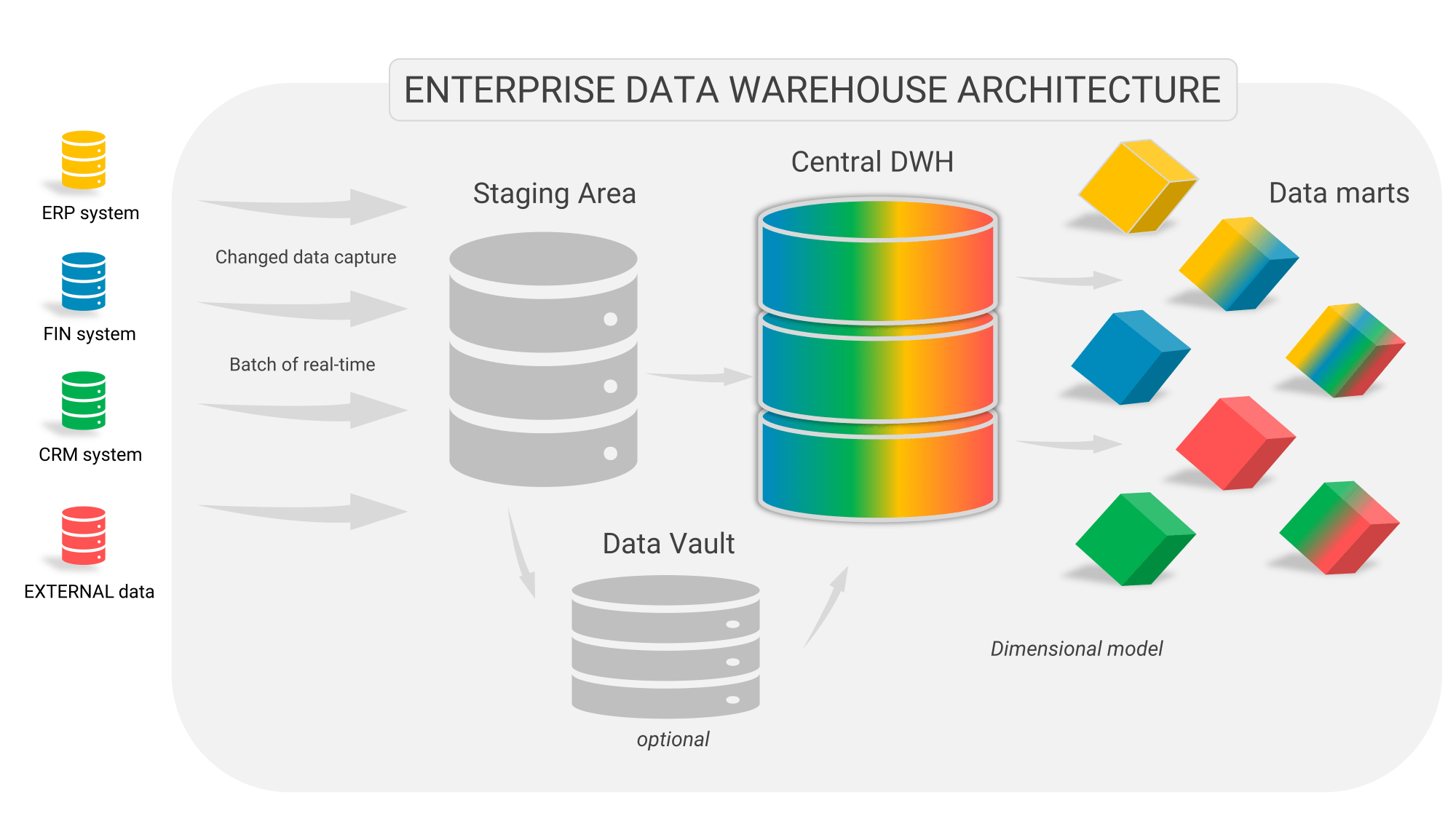 Figure 6: The complete architecture of a (real-time) data warehouse
Figure 6: The complete architecture of a (real-time) data warehouse
- When you start with BI & Analytics you first just pull a copy of your source system and put it on another server, you refresh it every night and then you start developing reports and dashboards on that. The costs are minimal and you can already get a lot of quick insight into your processes and results.
- In the next phase you develop a mini-data warehouse with some crucial facilities. These include capturing the data, transforming it into facts and dimensions, and aggregating the most important facts. So you unlock a few sources and integrate and summarize them. You take an iterative approach so that users can discover the added value and power of data warehousing.
- In the final stages of BI maturity, you start to think about how to build a complete enterprise data warehouse that unlocks all the necessary internal and external sources. Again, this is not a “big bang” scenario where the data warehouse team can lock themselves away for a few years, but you let the team build the architecture iteratively, in close collaboration with the expert users.
Do not let (external) consultants tell you that you can start immediately with a complete enterprise data warehouse. There are far too many risks involved. The chances of failure are high and BI often gives you only one chance to score.
Data warehousing & data modeling
The different schools of data warehouse modeling all have similarities in certain respects but none constitute the ideal data warehouse architecture in all situations. Here we briefly describe the main similarities and differences between all the ways you can model your data in your data warehouse database:
- The Ralph Kimball school: the enterprise data warehouse (EDW) and data marts are modeled with fact and dimension tables. A fact table with multiple dimension tables forms what is known as a star schema data warehouse.
- The Bill Inmon school: the third normal form (3NF) is leading the data modeling of the enterprise data warehouse. The third normal form is also used in many IT systems because it shows the golden mean between storage space and speed. The data marts are shaped with a star schema.
- The DataVault school: store the data in a so-called Data Vault with a very flexible data model after which you transform and store the data in a Business Vault, the equivalent of an enterprise data warehouse. You model the data marts as star schema.
The main similarity between these different architectures is that you always model the data mart according to a star schema. You can find an example of a star schema in Figure 7.
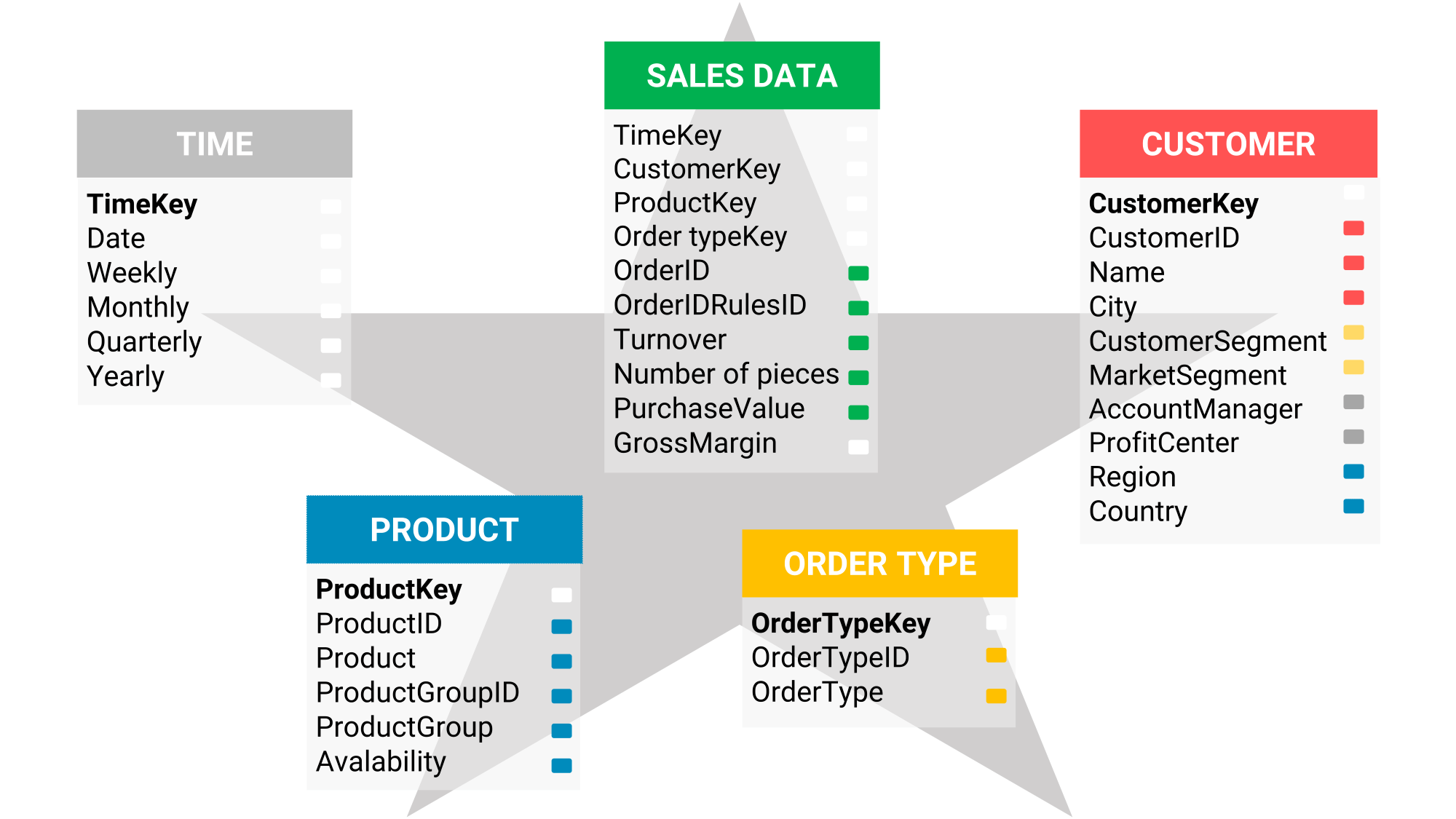 Figure 7: an example of a star schema according to data warehousing modeling
Figure 7: an example of a star schema according to data warehousing modeling
And that makes sense because the data analyst or report builder just wants to see, after logging in to the data warehouse server, the simplest possible representation of the data and does not want to be required to tie all kinds of tables together as shown here.
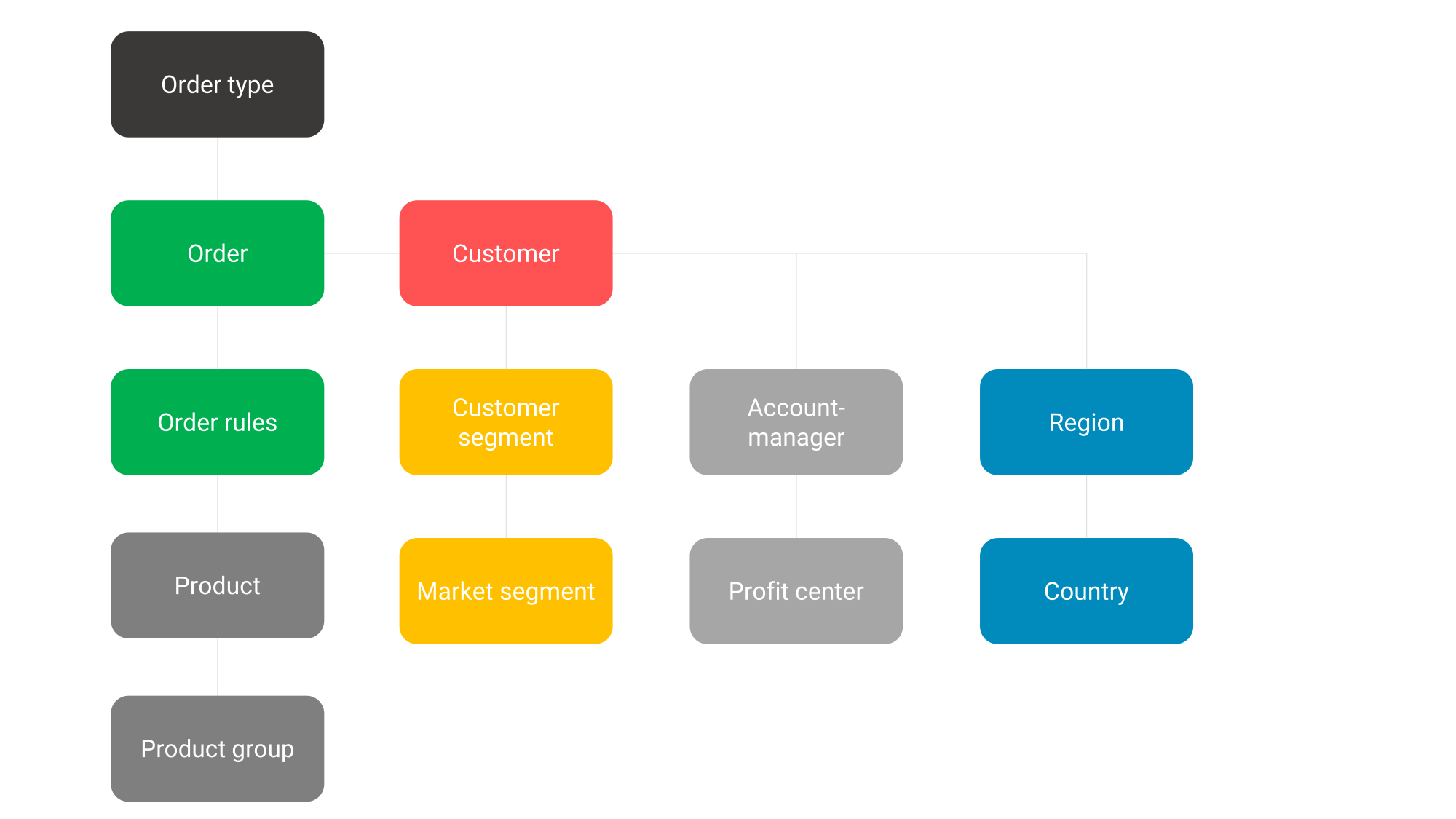 Figure 8: You build the star schema from many different tables. In the star schema, you reduce these 12 tables to just five.
Figure 8: You build the star schema from many different tables. In the star schema, you reduce these 12 tables to just five.
Whichever way you look at it, the star schema is the endpoint you are working towards in data warehousing. The road to that is not particularly captivating from a business perspective.
Not so fascinating at first
There are plenty of arguments to be made as to which data warehousing model your organization should choose, but they aren’t particularly exciting for organizations where data analytics is still in its infancy. Then you just want to achieve a return on data warehousing and BI as quickly as possible and choose the simplest, most transparent methodology: Kimball. At higher maturity levels, however, arguments other than “fast return” may weigh more heavily. Would you like independent advice on this or would you like to organize an internal workshop? Then contact us here.
The “data vault vs data warehouse” debate
As discussed earlier, a battle can ignite in which the Data Vault and the data warehouse are played off against each other. This is undesirable and also unnecessary because the actual advantages and disadvantages of the data vault methodology should speak for themselves. Yet time and again we find that organizations are seduced by (external) consultants who know how to present a Data Vault (plus BusinessVault) as a full data warehouse and at the same time downplay the complexity of a Data Vault. In any case, be on your guard when a Data Vault is in the picture in your organization; in that case, feel free to talk to the Passionned consultants.
The data lake versus the data warehouse
A data lake warehouse and a normal data warehouse must be interpreted and positioned differently, so there is no such thing as a ‘data warehouse data lake’. In a data warehouse you bring together structured data, in a data lake you store unstructured data (the big data) such as sound clips, documents, photos, videos, sensory data, and e-mails. In a so-called big data warehouse, you bring these two types of data together. A so-called data warehouse conducts the two types of data together when and where needed. So there is no need to discuss ‘data lake vs data warehouse’, they are two totally different repositories for different types of data. In a data lake, you store the big data, in a data warehouse you store structured data that fits into tables with rows and columns. The conductor brings them together.
Books about data warehousing
Data warehousing is a crucial tool for more effective BI & Analytics. Brush up on your knowledge of data warehouses with one or more of the following books.

- Daan van Beek’s Data Science book. In the total approach that Daan describes in his book, the data warehouse occupies a crucial place: the heart of the intelligent organization. All architectural aspects and data warehouse processes are discussed in detail. Order this book here.
- Data as a service. This book by Pushpak Sarkar takes you into the world of data warehouses, ETL, EAI, and data analysis. Click to see the book.
- The Data Warehouse Toolkit: The Definitive Guide to Dimensional Modeling. In this book by Ralph Kimball and Margy Ross, the authors take you through the craft of dimensional modeling, ETL, and various modeling techniques. This book comes with many examples from various disciplines and industries including retail, inventory, order processing, financial institutions, telecom, education, and insurance. Click to see the book.
- Building the Data Warehouse by Bill Inmon. This book has not been changed since 2002 but is still extremely relevant. This classic is not to be missed in the series of books on data warehousing. Order the book here.
With these books in your toolbox, you will lay a solid foundation for both the organizational side of BI, the process side of ETL, and the technical side of data warehouses. For even more in-depth knowledge and practical application, check out our data warehouse training course.
Delve deeper into data warehousing & analytics here
Do you also want to set up a successful (logical) data warehouse?
We would be happy to help you with the data warehouse business case, design tips, an appropriate and solid DWH architecture, and implementation. Our data warehouse specialist will be happy to discuss the challenges you and your organization face.
About Passionned Group
![]() Passionned Group is a leading analyst and consultancy firm specializing in Business Analytics and Business Intelligence. Our passionate advisors assist many organizations in selecting the best Business Analytics Software and applications. Every two years we organize Dutch BI & Data Science Award™.
Passionned Group is a leading analyst and consultancy firm specializing in Business Analytics and Business Intelligence. Our passionate advisors assist many organizations in selecting the best Business Analytics Software and applications. Every two years we organize Dutch BI & Data Science Award™.



