
Learn all about ETL & Data Integration Tools, data replication, and governance
The ETL & Data Integration Guide™ 2025 makes tool selection very easy. This guide provides you with all the knowledge and resources you need to analyze and assess the ETL vendors (20+ vendors are covered like Informatica, SAP, Microsoft and so on). In doing so, you’ll automatically drill down to the core of other important data warehouse processes, such as data integration, data migration, data quality, and data governance. By consulting this guide to ETL tooling regularly, you will move through a rapid learning curve. Keeping up with the profession and evaluating the available ETL & data integration tools has become a lot easier and more accessible with this unique, interactive guide. From now on, you start every discussion with colleagues, vendors, or clients from a solid, comfortable pole position. Download the ETL & Data Integration Guide now.
Why buy the ETL & Data Integration Guide?
The ETL & Data Integration Guide™ is specifically designed for BI consultants, data architects, data engineers, IT managers, project managers, and BI managers. But general managers and consultants will also benefit from it. What exactly is the use for you as a manager, professional, or (external) consultant of the ETL & Data Integration Guide? The most popular applications of this guide are:
1. Vendor and tool selection: easily compose a shortlist
Evaluate each vendor based on functionality and market dominance. Apply the principle of “what matters most should matter most” and draw your own conclusions. Quickly compile a long- and shortlist of vendors that qualify and meet your selection criteria and specific business situation. Closely monitor the performance of the selected ETL software vendor(s) that best address the needs and requirements of your organization, division, or business unit.
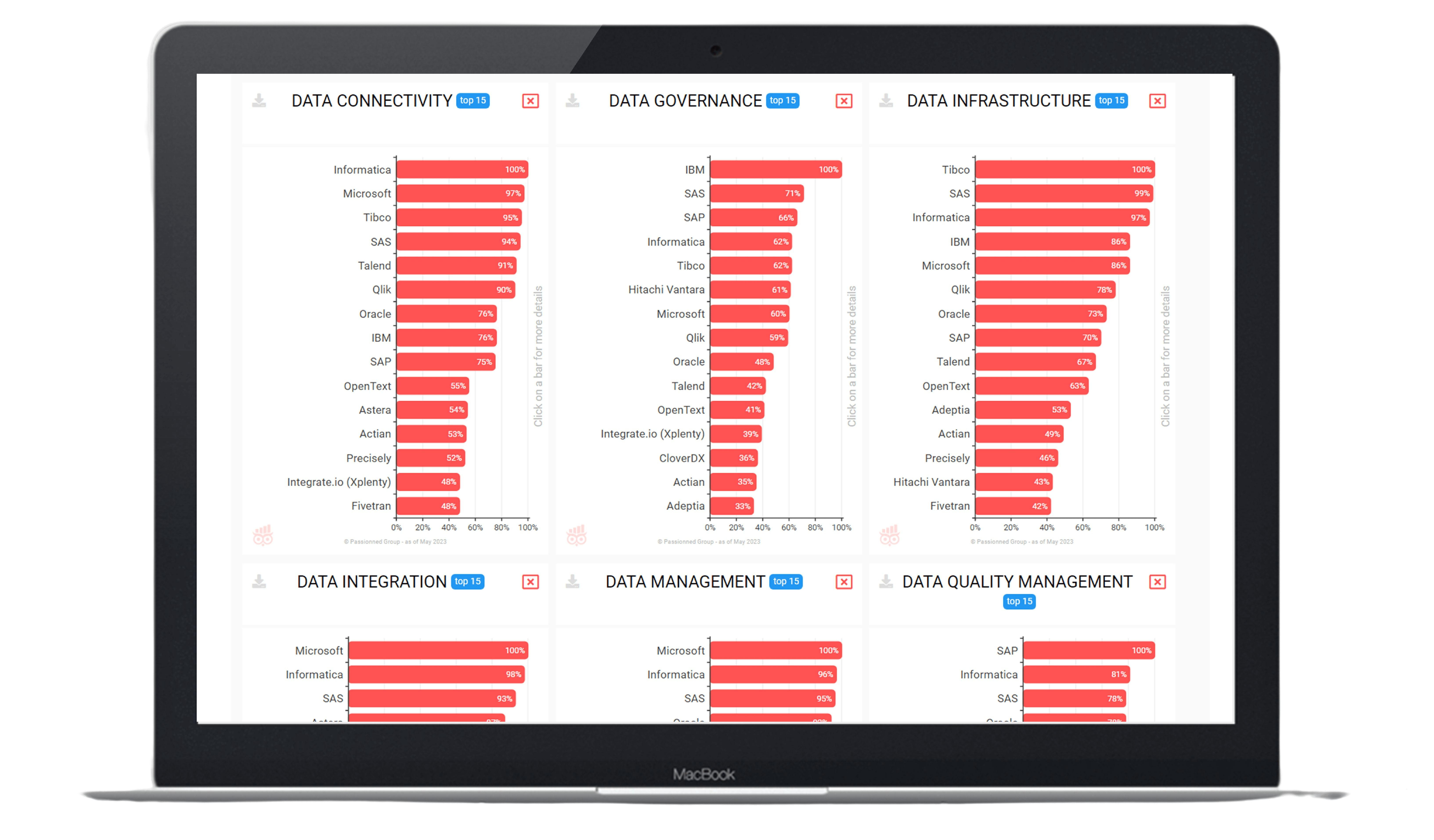 Figure 1: Initially you see the ranking of the various suppliers on 9 main categories, but you can easily drill down and zoom in on detailed aspects. The ratings presented in the above figure are not complete and should not be used to draw any conclusion.
Figure 1: Initially you see the ranking of the various suppliers on 9 main categories, but you can easily drill down and zoom in on detailed aspects. The ratings presented in the above figure are not complete and should not be used to draw any conclusion.
With the self-service analysis module (an extra option available at a small additional fee) you manage everything yourself. You select the ETL tool vendors you want to keep an eye on and you choose the functionality you want. This way you compose your own top 3 ETL tools based on, for example, 50 criteria that are specifically important to you. Drill down to four levels to get to the core of the field and learn all the ins and outs of the most important ETL processes, such as data integration, data migration, data replication and data governance. Download any relevant graph to add liveliness to any presentation.
2. Training and education: develop yourself and your team
Broaden, deepen, and polish your knowledge as a data manager or consultant. Use this online guide as a training tool for yourself and your project team. Work through all the relevant definitions and jargon and get inspired by the valuable ideas in the online video library.
 Figure 2: The training module contains more than 300 videos and helps you master data integration and ETL quickly. But the guide directs you to many more relevant videos such as vendors’ product videos and ETL expert talks.
Figure 2: The training module contains more than 300 videos and helps you master data integration and ETL quickly. But the guide directs you to many more relevant videos such as vendors’ product videos and ETL expert talks.
Expand your domain knowledge and increase your market value as a manager or specialist by diving into the hundreds of (instructional) videos, learning modules, TED talks, online courses, and so on.
 Figure 3: Multiple videos on data modeling illustrate, among many other things, the characteristics of star schemas versus snowflake schemas.
Figure 3: Multiple videos on data modeling illustrate, among many other things, the characteristics of star schemas versus snowflake schemas.
Discover the difference between ETL and ELT by watching an animated video, or follow a mini-course on data lakes, data warehouse automation, and the importance of data quality. Learn from an ETL expert why validation, logging, and rerunability of ETL data are indispensable functionalities.
In addition, with our guide you always stay on top of the news: consult all enlightening news items related to the field of data warehousing in general and top ETL tools in particular. Increase your understanding of what is going on and get a realistic picture of how the ETL market works.
Main topics: 250+ selection criteria included
In total, several dozen main topics (selection criteria) are included in the ETL & Data Integration Guide. Each main topic also contains a large number of sub-topics and selection criteria. The topics and videos included in this guide are updated regularly.
✪ Change Data Capture
✪ Cloud first: ETL-as-a-Service
✪ Connectivity
✪ Database normalization
✪ Data governance
✪ Data integration
✪ Data quality
✪ Data lineage
✪ Data management
✪ Data migration
✪ Data pipelines
✪ Data replication
✪ Data Vault
✪ Data Virtualization
✪ Debugging ETL Tools
✪ DWH appliances
✪ Generative AI
✪ Impact Analysis
✪ Infrastructure
✪ Job scheduling
✪ Master Data Management
✪ Meta data management
✪ ETL model
✪ ETL platform
✪ Full load vs incremental load
✪ Massively Parallel Processing
✪ Open-source ETL tools
✪ Slowly Changing Dimensions
✪ Staging Area
✪ Star scheme + snowflake
✪ Synthetic data
✪ Test data
✪ Workflow ETL
This is just a first selection from the extensive learning material and development potential of our ETL & Data Integration Guide. In addition, you will naturally learn how the market and ETL processes function. But also which vendors are the most innovative, what their specializations are and where their distinctive power lies. You can verify yourself how a specific vendor scores on each topic, on outlines and details, and what its strengths and weaknesses are. Get the most out of the ETL & Data Integration Guide 2025 today and download the guide here.
The vendors and their products
The ETL & Data Integration Guide 2025 covers at least 20+ leading ETL software vendors along with their products and services. Although market consolidation has reduced the number of vendors, there are big differences. Some vendors can be labeled as a “one trick pony” (no disrespect intended), while others deliver a complete, integrated portfolio. The following ETL vendors are covered in our guide:
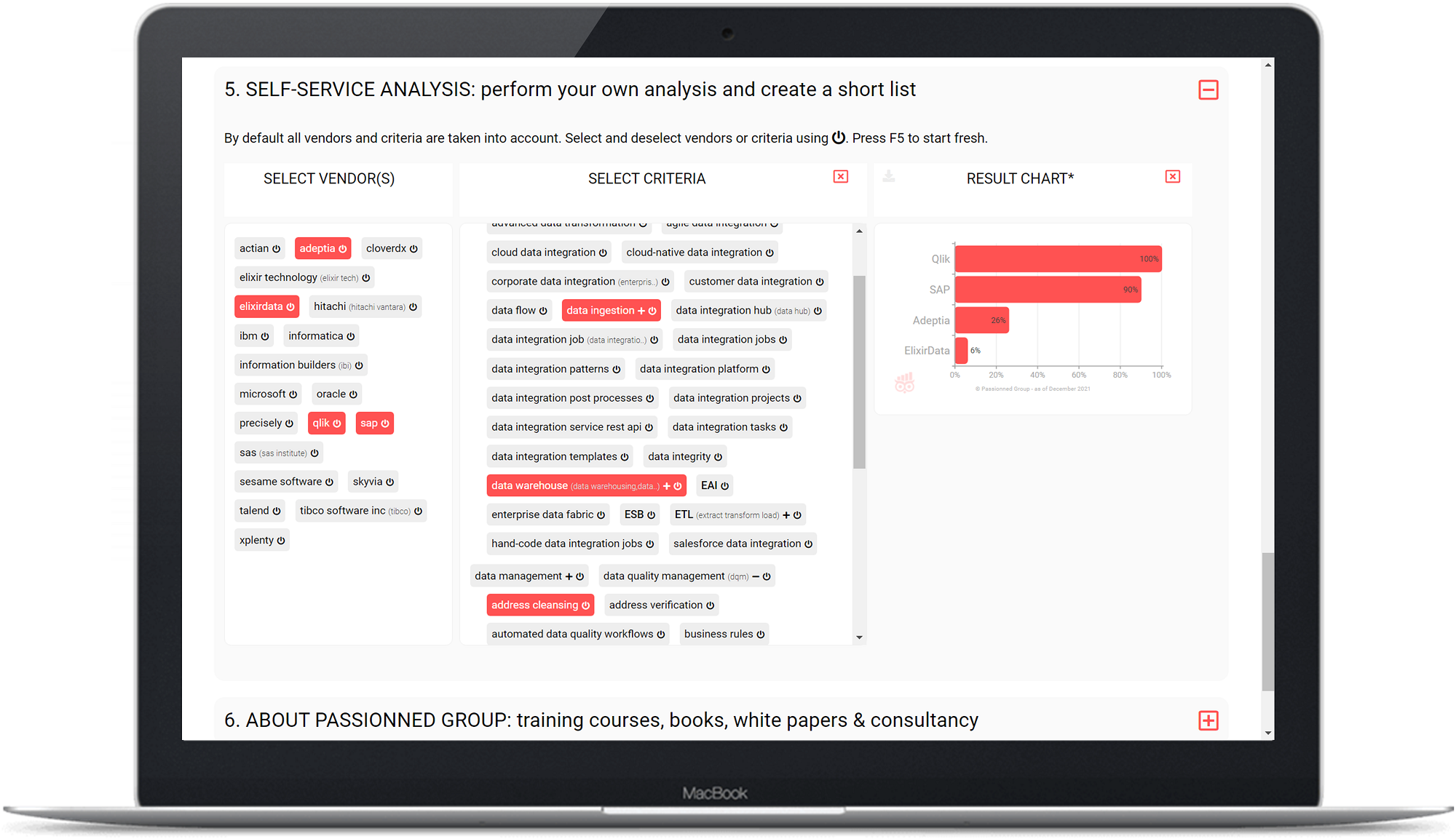
Figure 4: Example of the self-service functionality of the ETL & Data Integration Guide. The ratings shown here are completely arbitrary and serve only to illustrate the module.
Click on an ETL vendor and you will see all the software products of that particular vendor. Are you missing a particular vendor or product? Please let us know and we will add it to our guide without any charge.
Actian Avalanche - Actian Dataconnect - Actian Dataflow - Actian Data Integration - Actian Nosql Object Database - Actian DataConnect Studio
✪
Adeptia Connect - Adeptia Suite - Adeptia Integration - Adeptia Server
✪
Astera Centerprise - Astera Data Stack - Astera DW Builder - Astera API Management - Astera ReportMiner - Astera Data Integration
✪
CloverDX Server - CloverDX Designer - CloverDX Data Integration - CloverDX Data Management - CloverDX Data Quality - CloverDX Data Services
✪
Databricks Unity Catalog - Databricks Connect - Databricks Platform
✪
✪
✪
Pentaho Data Integration - Lumada Data Catalog - Lumada Edge Intelligence - Lumada Data Optimizer - Lumada Data Integration - Lumada Data Services - Pentaho Community Edition - Lumada Data Lake - Hitachi Lumada portfolio - Pentaho Data Services
✪
IBM Infosphere - IBM Infosphere Information Server - Tivoli - IBM Data Replication - Infosphere Information Analyzer - IBM Infosphere Datastage - Q Replication - IIDR - Infosphere Change Data Capture - IBM Infosphere Information Analyzer - IBM Data Server - Tivoli Enterprise Data Warehouse - Infosphere Replication Server - IBM Zhyperwrite - IBM Data Integration - Infosphere Information Server Data Quality - IBM Data Quality - IBM BigIntegrate - InfoSphere Master Data Management - IBM Integration Bus - IBM InfoSphere FastTrack - IBM Cloud Paks
Powerexchange - Informatica PowerCenter - Informatica Intelligent Cloud Services - Informatica Big Data - Informatica Data Quality - Informatica Big Data Management - Informatica Cloud Data Integration - Informatica Data Replication - Powercenter Big Data - Powercenter Data Virtualization - Powercenter Data Integration - Informatica Data Integration - Informatica Cloud Data Replication - Informatica Cloud Data Profiling - Informatica Mass Ingestion - Informatica Big Data Parser - Informatica Data Quality Platform - Informatica Master Data Management - Informatica PowerCenter Data Quality - Informatica Metadata Manager - Informatica Big Data Integration - Informatica PowerCenter Data Profiling
✪
✪
Azure Data Factory - Microsoft Azure - Azure Data Lake - Azure Synapse Analytics - DQS - Microsoft Dataverse - Azure Databricks - Microsoft Products - Sql Server Integration Services - Azure Purview - Azure Data Studio - Microsoft Power Platform - Azure Data Catalog - Microsoft Fabric - Azure Data Explorer - Sql Data Sync - Microsoft Purview - Azure Data Services - Azure Integration Services - Sql Server Data Quality - Sql Server Database Replication - Azure Blob Storage - Azure Data Warehouse - Microsoft Sql Server Replication - Azure SQL Server Replication - Microsoft Azure Synapse Analytics
✪
OpenText Gupta - OpenText Magellan - OpenText InfoArchive - OpenText Business Network - OpenText Connect - OpenText Contivo - OpenText Big Data - OpenText Magellan Data Discovery - OpenText Analytics - OpenText BizManager - OpenText Solutions - OpenText Active Catalogue - OpenText MIM - OpenText Anywhere
✪
Oracle Data Integrator - Oracle Goldengate - Oracle Enterprise Data Quality - Oracle Warehouse Builder - Oracle Streams - Oracle Data Integration - Oracle Autonomous Data Warehouse - Oracle Data Quality - Oracle Datalens Server - Oracle Data Integration Platform Cloud - Oracle Streams Replication - Oracle Data Profiling - Oracle Product Data Quality - Oracle Metadata Management - Oracle Data Catalog - Oracle Database Replication - Oracle Service Bus - Oracle Data Fabric
✪
Precisely Connect - Precisely Data Integration
✪
Qlik Replicate - Qlik Compose - Attunity - Qlik Data Integration - Qlik Catalog - Qlik Cloud Data Integration - Qlik DataTransfer - Qlik Data Exchange - Qlik Lineage Connectors - Qlik Salesforce Connector - Qlik Automation
✪
SAP HANA - SAP Data Services - SAP BW - SAP Master Data Governance - SAP HANA Smart Data Integration - SAP Data Warehouse - SAP Data Hub - SAP Data Quality Management - SAP Replication - SAP Replication Server - Powerdesigner - SAP Netweaver BW - SAP LT Replication Server - Sybase Replication Server - SAP Master Data Integration - DQM Microservices - SAP BW Data Integration - IBP Data Integration - SAP Data Integration - SAP Netweaver Pi - S/4hana Smart Data Integration - SAP Data Intelligence Cloud - SAP IBP - SAP NetWeaver MDM - SAP TDMS - SAP Data Intelligence Modeler
✪
SAS Viya - SAS Data Integration - SAS Data Integration Studio - SAS/ACCESS - SAS Data Quality - SAS Data Management - SAS Metadata Server - SAS ETL - SAS Data Loader - SAS Business Rules Manager - SAS Data Preparation - SAS Clinical Data Integration - SAS Data Surveyor - SAS Data Quality Server - SAS OLAP Server - SAS Data Governance - SAS Data Quality Accelerator - SAS LASR Analytic Server - SAS Data Integration Server - SAS Data Explorer - SAS Enterprise Data Integration Server - SAS Data Studio - SAS Metadata Bridge - SAS Data Management Studio - SAS Data Warehouse - SAS Event Stream Processing - SAS Lineage - SAS Dataflux Data Management
Relational Junction - Sesame Software Relational Junction
✪
✪
SnapLogic Intelligent Integration - SnapLogic Flows - SnapLogic AutoSync - SnapLogic Fast Data Loader - SnapLogic Patterns Catalog - SnapLogic Data Catalog
✪
Snowflake Data Cloud - Snowflake Marketplace - Snowflake Data Warehouse - Snowflake Cloud Data Platform - Snowflake Data Platform
✪
Talend Data Fabric - Talend Open Studio - Talend Data Catalog - Talend Data Integration - Talend Data Preparation - Talend Data Management - Talend Data Quality - Talend Cloud Integration - Talend Pipeline Designer - Talend Cloud Data Integration - Talend CDC - Talend Administration Center - Talend Metadata Manager - Talend Data Console
✪
Omni - Gen - Tibco Webfocus - Tibco Data Virtualization - Tibco Cloud Integration - Tibco MDM - Tibco Enterprise Message Service - Tibco Messaging - Tibco Streaming - Tibco Enterprise Administrator - Tibco Data Quality - Tibco Data Migrator - Tibco Data Management - Tibco Community Edition
If you prefer, you can also zoom in on the radar graphs. In addition, the ETL & Data Integration Guide also contains line graphs that allow you to visualize the progression and ratings of vendors over time. This also gives you direct insight into the development speed of the software vendor.
The ETL & Data Integration Guide 2025 is the first digital guide that is 100 percent based on facts (and AI) and not just opinions or views. All relevant data is inspected carefully, and has been objectified and validated.
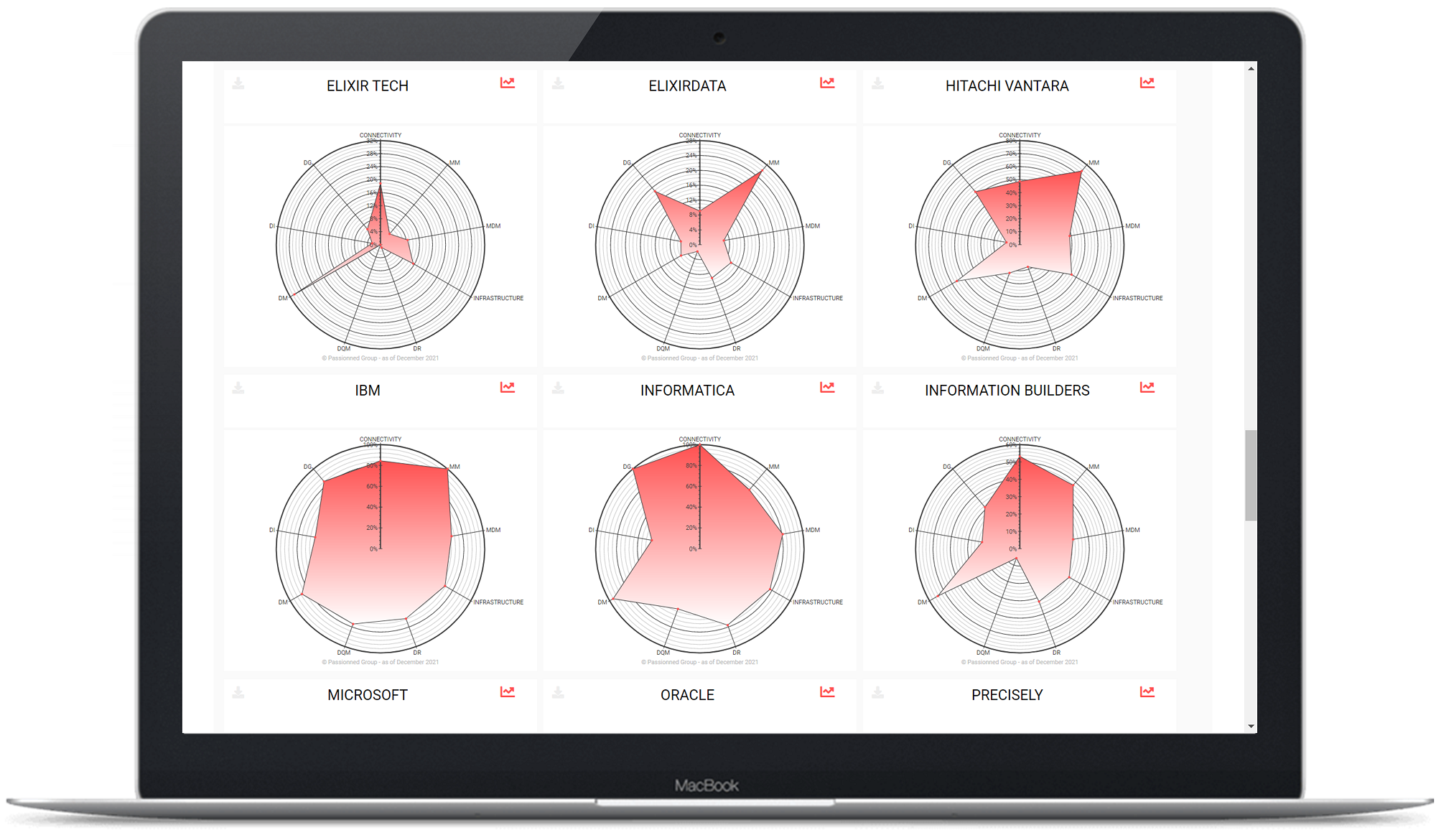 Figure 5: The radar graphs shows in outline how the supplier is doing. The scores shown here are completely arbitrary and serve purely to illustrate the feature.
Figure 5: The radar graphs shows in outline how the supplier is doing. The scores shown here are completely arbitrary and serve purely to illustrate the feature.
Master the field of data integration, data warehousing, and ETL down to the finest details and henceforth steer any BI or data warehousing project in the right direction.
The 5 main benefits of this guide
- it contains updates renewed quarterly that provide you with the latest trends
- it is 100% objective, we have no preferences or commercial ties
- it contains a clear structure and is richly illustrated with charts
- you will save research time, by having all the information concisely in one place
- you will strengthen your negotiation power
Download the ETL & Data Integration Guide 2025 now
Do you want to be guided by a good, 100% vendor-independent guide for tool and vendor selection? Do you also want to learn more about the field? Try it out: for € 290 you will be sitting in the front row from now on.
If you would like to pay at a later time, consult us here.
About the author Daan van Beek MSc
 Daan van Beek MSc, has developed this ETL comparison guide, based on more than 20 years of experience as a BI & data architect. He has been monitoring and analyzing the ETL market since 2004. Daan enjoys sharing his philosophy and ideas on BI, data management, and AI with students and managers during lectures, workshops, and in-company trainings.
Daan van Beek MSc, has developed this ETL comparison guide, based on more than 20 years of experience as a BI & data architect. He has been monitoring and analyzing the ETL market since 2004. Daan enjoys sharing his philosophy and ideas on BI, data management, and AI with students and managers during lectures, workshops, and in-company trainings.
He gives master classes on BI & Artificial Intelligence in Asia, North and South America and South Africa. Big Data & BI are the main modules that he teaches at the well-known business schools TIAS and EUR.

