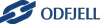Six criteria for measuring data quality
Data quality can be measured. It is complex, but certainly not impossible. The following aspects are used as criteria to measure data quality:
- Accuracy: consider, for example, old addresses or spelling errors in names and addresses.
- Completeness: has all the data been entered completely and correctly? Your processes will also benefit from this and run more smoothly.
- Format: does the data comply with the rules? Consider the formatting of phone numbers or bank accounts.
- Consistency: is the data consistent across internal databases? For example, is an address in the bookkeeping solution identical to the one in the CRM system?
- Duplication: customers often appear multiple times in files. Often, the information in various records is different.
- Integrity: is the data linked with the relevant information? Consider orders that “float” in the system and aren’t attached to any customers.
Invest in good customer data. Regularly test for all of these criteria. There are many external tools and sources available for this. Consider tables with postal codes or systems to check customer names. Or check out the ETL data profiling tools: here you will find an extensive overview.
 Figure 1: Start measuring your data quality so you can know where to improve it.
Figure 1: Start measuring your data quality so you can know where to improve it.
Go from measuring to improving
Measuring is the first step, but it’s not the end of the road, of course. Step two is improving your own data. And to do that, you need a good method. Our approach helps you and your team learn new skills and competencies, so you can continuously improve the quality of your data. And we’ll give you the right tools, so that you and your team can achieve better results.
You’ll be able to assess your data quality at any time, and see how and where it can be improved. It doesn’t matter if it’s about customer data or all kinds of product and process data. A good place to start is Deming’s famous plan, do, check, act cycle. This allows you to periodically improve your data quality from a plan.
Dive deeper into data quality directly here
Set goals for your data quality
You have to set goals for your desired data quality. Make them SMART so they can be measured. Then, determine key performance indicators (KPIs) and place them on a dashboard. The next step is setting a target for the KPIs. For example, making sure that 98% of customer contact information is correct.
The “do” step is about performing analyses. Check for incorrect data and how it can be corrected, either on the spot or by adjusting the system. During the “check” step of PDCA, compare the target with the results, and discuss the findings with your peers and colleagues. For the last step, reevaluate your targets and KPIs or free up more resources for execution.
What else should you know about data quality?
Data quality has several important aspects. These always have to be considered in your approach. Overlooking these aspects can damage your reputation, and your customers might abandon you. Data needs to be carefully secured. Always pay attention to the following factors:
- Privacy is an important aspect. Your customers are trusting your organization with their personal information. They assume you’ll handle it carefully. There was controversy when several large banks wanted to sell customer data to third parties, seeing it as an extra revenue source. This is a breach of trust and leads to loss of reputation.
- Security is another very important aspect. Almost every day, there’s a news item about a breach of personal information in an online database: a hack. These companies suffer massive reputation damage. It can even endanger your company’s continued existence.
- Transparency is becoming increasingly important. What customer data do you store, and what data can you pass on to third parties? Facebook is the most famous example. They store a lot of data about their clients, making it unclear what data they store and what they’re doing with it.
These aspects are becoming more important. They’re always on management’s and the directors’ agenda.
The ETL & Data Integration Guide The ETL & Data Integration Guide™ gives you unlimited access to large amounts of market, product and vendor information. Evaluate the leading vendors on various aspects including data quality. Use it to select the most suitable data integration solution and take your knowledge to the next level. Drilldown to as deep as four levels, this is how you get to the heart of the field. Get to grips with key ETL processes, including data quality, data integration, data migration, data replication and data governance. Discover the difference between ETL and ELT by watching an animated video, or follow a mini-lecture on the importance of data quality.
The ETL & Data Integration Guide™ gives you unlimited access to large amounts of market, product and vendor information. Evaluate the leading vendors on various aspects including data quality. Use it to select the most suitable data integration solution and take your knowledge to the next level. Drilldown to as deep as four levels, this is how you get to the heart of the field. Get to grips with key ETL processes, including data quality, data integration, data migration, data replication and data governance. Discover the difference between ETL and ELT by watching an animated video, or follow a mini-lecture on the importance of data quality.
Data in all shapes and sizes
Data comes in many shapes and sizes. The most famous kind is Big Data. This is a very large and complex volume of data that no longer fits in a standard database of columns and rows. But you also have to pay attention to open data and zero data.
 Big Data: a very important trend. In this data-driven economy, big data can quickly provide new insights into the behavior of customers and devices. Big Data is figuratively looking for the needle in a haystack. If you work with big data, you’re likely to have problems with data quality. Especially when it concerns data posted on social media.
Big Data: a very important trend. In this data-driven economy, big data can quickly provide new insights into the behavior of customers and devices. Big Data is figuratively looking for the needle in a haystack. If you work with big data, you’re likely to have problems with data quality. Especially when it concerns data posted on social media.- Open data: is freely available data. These days, it can be pulled from countless sources. Governments and knowledge institutes are producing data non-stop. The goal of open data is reuse. By linking it with company data, you can greatly enrich your customer data and gain a lot of insight into your customer or problem.
- Zero data: many organizations only focus on big data, because that’s the trend. They forget that a lot of data is also internally available. For example by specifically looking at data that’s not in your database. We call this zero data. This data tells you, for example, what your customers didn’t buy.
 Big Data: a very important trend. In this data-driven economy, big data can quickly provide new insights into the behavior of customers and devices. Big Data is figuratively looking for the needle in a haystack. If you work with big data, you’re likely to have problems with data quality. Especially when it concerns data posted on social media.
Big Data: a very important trend. In this data-driven economy, big data can quickly provide new insights into the behavior of customers and devices. Big Data is figuratively looking for the needle in a haystack. If you work with big data, you’re likely to have problems with data quality. Especially when it concerns data posted on social media.What do our clients say?
“The assignment was done very well by the consultants of Passionned Group, sharp organizational advice and excellent cooperation.”
The three most commonly-made mistakes
There are pitfalls to consider. Learn from mistakes others have made before. These are the 3 most commonly-made mistakes in data quality.
- Thinking of data quality as a one-time exercise instead of a continuous improvement process. When the immediate need for good data becomes less urgent it disappears from the agenda. Without a continuous process, it’s a drop in the ocean.
- Not considering data a strategic asset. In these cases people may occasionally pay attention to data quality, but it’s not structurally embedded. You can change this by continuously monitoring and reporting on data quality.
- Thinking that data quality should be governed by IT. The responsibility isn’t equally distributed. Improving data quality never really takes off.
Improve data quality in your company
Data quality is an active topic in every data-driven organization, and it’s only becoming more important importance. Do you want to set goals for your data quality? Let our experts help you. Contact us for more information or a consultation.