Definition of BI self-service
To fully understand the concept of BI self-service we will give a definition:
Definition of BI self-service: the concept with which BI end users and analysts can quickly create data sets themselves based on controlled or uncontrolled, internal and external data sources, and visualize the data therein and can share the resulting insights with others.
The suppliers address a common problem with self-service BI: IT is not always able to quickly satisfy the acute information needs of end-users or analysts. This is especially true when the organization already has access to a data warehouse and then sometimes it takes weeks or months before IT has made the requested IT data sets available.
The business needs the insights now, because the world might look completely different tomorrow. Users sometimes choose to download a BI tool out of desperation or to activate it in the cloud and then take a shot at it themselves. Does this not cause the organization to return back to the pre-BI era?
Long live self-service BI
Self-service is an unstoppable trend that seamlessly fits into the concept of the intelligent organization, as self-service can enable:
- Cheaper services or products or more added value: dependent on the strategy of the organization, they will translate to either a greater number of marginal, cheaper products, or a higher quality of service.
- Faster processing: there are usually fewer links required in the process, by which it can, in theory, be carried out faster.
- More flexible and less dependent: the customer can largely determine for himself where, when, and what is done. Chances are, however, that mistakes are made because the essential knowledge is lacking. Who has never put together an Ikea cabinet and afterwards been left with one puzzling screw remaining? Which means that the cabinet is not stable on its base and has to be put back together again.
- A more active relationship: the customer becomes more closely involved in the implementation of the process so that a more active involvement with the organization can emerge.
If you want something done right…
Yesterday, my 65-year old neighbor sighed, ‘I have to do everything myself these days’. Before he could go to the hospital for a check-up he first had to enter a lot of data on my.hospital.com. He was asked every question imaginable about his identity, place of residence, and physical condition. He continued, ‘The hospital employees used to do that themselves!’
Somehow, I understood him. The downside of self-service for the customer is that now, the customer has to do more. What is the other downside? In other words: who benefits from this and when? And can that be extended step by step to BI-self service? And how does it work? What should an organization do with it?
One can no longer avoid self-service in our society
Organizations thus end up outsourcing a portion of their business processes and do this to the customer or the supplier. You can fill out your own police reports online for certain things, you put together Ikea furniture and at the supermarket you fill your own shopping trolley, and nowadays you even pay the bill yourself.
In many cases, you no longer even need a supermarket employee. Specific technology makes self-service possible. With reports, it is the internet and integration technology, among other things, that enters the reports in the police system behind the scenes. In the supermarket, this includes the bar codes and the self-service cash register systems.
Self-service can also go horribly wrong
In practice it shows that self-service can also go horribly wrong. Employees of a bank that have implemented far-reaching self-service cannot even advise the client on what type of account he should open on the internet! An expensive repair man must eventually be hired for the Ikea cabinet. In short, self-service without service. It is therefore conceivable that the customer will then just develop an aversion to the company.
Open the BI & Analytics Comparison Guide™ 2024 The BI & Analytics Guide 2024 will help you choose the right BI tool for your organization. Compare tools on any criteria, including self-service analytics functionality. Gain insight into every tool and function thanks to the unique drill-down functionality and knowledge library.
The BI & Analytics Guide 2024 will help you choose the right BI tool for your organization. Compare tools on any criteria, including self-service analytics functionality. Gain insight into every tool and function thanks to the unique drill-down functionality and knowledge library.
Self-Service BI
Can the self-service concept be translated into Business Intelligence, and if so, how? Do the same principles apply there? Broadly speaking, this is the case above all with regard to the aspects of speed and flexibility. The following table shows where the greatest advantages of BI-self service are.
| Cheaper or more added value | The IT department can focus on the infrastructure, the supply of ready-made components, and more complex data sets. The simple tasks can now be outsourced to the users. |
| Faster | Users can gain new insights much faster. At the same time, they can experiment, and in doing so, help IT to develop and validate new data sets in a relatively short time. |
| More flexibility | The users are flexible and much less dependent on IT. |
| More active relationship | Depending on other factors, including the role of the BI manager. |
The preferred BI of the future
Many of the BI vendors are trying to promote BI self-service. They are marketing this principle almost excessively and are presenting it as the preferred BI of the future. A part of the market now has the perception that end users (have to) be able to do everything. A complex report or a dashboard can be compiled with a few clicks. But is that perception justified?
This form of agile BI causes the BI manager lot of headaches:
- How can self-service users be prevented from producing nonsense? After all, linking tables is usually not simple and very complex for the average user. Let alone the need to link internal and external (big) data sources.
- How can it be prevented that multiple versions of the truth will be created together?
- How can a patchwork of BI tools be prevented from coming into the organization?
A difficult dilemma
The experienced BI manager experiences self-service BI as a difficult dilemma. He will, on the one hand, not want to lose control of BI and also not want the carefully constructed single version of the truth to be exposed to ‘outside attacks’. He fears that users can now not only arrive at new reliable insights with lightning speed, but also at terribly wrong insights.
On the other hand, he will not be able to deny the existence and benefits of BI self-service: to quickly be able to experiment with potentially valuable data sets and react more quickly to developments. He is wise not to throw the baby out with the bath water. It can be thought to develop a BI self-service policy that takes into account the accountability and complexity of data sets and the type of user.
| Controlled data sets | Uncontrolled data sets | |||
| Simple task | Complex | Simple task | Complex | |
| End User | Allow | Do Not Allow | Do Not Allow | Do Not Allow |
| Key User | Allow | Warn | Do Not Allow | Do Not Allow |
| Analyst | Pass to key user | Encourage | Allow Condition. | Allow Condition. |
This policy can force the BI manager arrange a process with the main users, analysts, and IT. And by commissioning the proper authorizations and workflow. And where necessary, to increase the knowledge and skills of main users and analysts. The exact interpretation of the policy can vary by organization, since the level of users and analysts differ, for instance. And there must also be room for experimentation and learning.
The ideal BI environment with self-service?
What does the ideal BI environment with self-service look like and who takes responsibility for what?
- IT ensures a solid, reliable information infrastructure with controlled data sets and ready-to-use, reusable components. And they provide a single BI platform that enables both standard reporting, dashboarding and self-service.
- Analysts can use self-service to experiment with controlled and uncontrolled data sets. They share new insights only when there is a guarantee that the information is correct.
- Main users can, based on ready-to-use components (KPIs and reusable insights), compile dashboards and simple reports on their own. This can be commissioned with a Business Intelligence Framework.
- The BI manager, together with the business managers, ensures that the experimental data sets are validated by domain experts. They will eventually want to include specific data sets in the organization-wide information infrastructure.
- The end user ‘only’ consumes the information.
Turn self-service BI into a success story
Business Intelligence is essential to the effective and efficient manage of any organization. Managers can’t get insights into operational performance fast enough. Fortunately for them, BI software is becoming easier and easier to use. Managers don’t have to rely on stressed IT staff to provide the right data anymore. Long live self-service BI! Right? Well, yes and no. There’s a danger to using data in this way. If you don’t take the limitations of self-service BI into consideration, its success rate is very slim. Our 6-step improvement plan reinforces the foundation of self-service BI.
In multiple reports, research and analyst agency Gartner presented its expectations for the future of self-service BI. As always, there are two sides to every coin.
Two sides of a coin
On the one hand, Gartner expects more data to be analyzed using self-service BI than Data Science in 2019. On the other hand, the researchers are pessimistic about the chances of success. Earlier, they predicted that probably only 1 in 10 projects is set up properly. Most projects run into data inconsistencies, which have to be avoided at all costs, as they negatively affect management decisions. Managing the data chaos that results from self-service Analytics can be a full-time job, Gartner warns us. Keeping the data secure and preventing data leaks also poses a great challenge.
Four practical problems with self-service BI
Besides data chaos, there are several persistent practical problems with self-service Business Intelligence. Below you’ll find four of them based on my own experiences and what I’ve encountered in the literature.
1. Inconsistent definitions
More people get access to the source data themselves, allowing them to make their own calculations. That leads to everyone having their own definition. Especially when certain definitions work to the advantage of the person in question. These definitions are often also not shown in the reports. That’s a shame, because you’re striving to maintain one version of the truth across the organization.
2. Wrong interpretations
Multiple definitions also lead to wrong interpretations, especially as data gets more complex and speed becomes an important factor. In the case of self-service BI, it’s likely that the reporting person doesn’t consider every factor in their calculations. For example, when British soldiers started wearing helmets in WWI, the number of reported head wounds increased. A wrong interpretation of this statistic could lead to the conclusion that the helmets were a mistake.
In our ongoing project in the municipality of Rotterdam, we experienced complex data leading to wrong interpretations more than once. When citizens who apply for benefits are supported by offering education and other options from the first intake onward, you expect commitment from those citizens.
Yet, the data seemed to show the opposite, at first glance. In the pilot program, it turned out that three times as many citizens “dropped out” and stopped showing up to follow-up appointments compared to the traditional approach. This high percentage of dropouts was seen as a negative at first, until further analysis proved that the new approach led to fewer citizens feeling the need to apply for benefits, because they got the help they needed. There was a lot of daylight between definition of the calculated numbers and the way they were interpreted.
3. Trivial KPIs spreading like wildfire
Managers love measurements. If the data is available, they can calculate to to their heart’s content. This leads to them developing tons of KPIs. Everything that can be measures is used to manage.
Focus on the vital few KPIs, not the trivial many.
Whoever took the Performance Management and KPIs training course knows that more isn’t always better, especially when it comes to KPIs. Not everything that can be measured is relevant from the perspective of management information. It’s all about the vital few KPIs, rather than the trivial many.
4. Inconsistent data
As we said earlier, speed plays an important part in self-service BI. The manager doesn’t want to wait for IT to deliver the numbers, which can take weeks. Speed wins over purity. If the data is available, they can immediately start calculating.
But herein lies another treacherous pitfall: the assumption that the data is correct and that the manager understands the data.
For a long time, the trend was to let everyone register as much data as possible, without checking to see if the data is actually necessary. Until recently, every employee in healthcare had to log a diary every 5 minutes, detailing everything that happened, as described in the Dutch Volkskrant. The healthcare secretary fortunately put an end to that. Seeing as the person registering the data often doesn’t benefit (directly) from the data at all, the odds are good that there are inconsistencies in the data, or at least that the data was registered incorrectly.
Apply our improvement method for BI self-service
How can you avoid these practical problems and pitfalls? A solid methodology when setting up self-service BI is a must. To make a project succeed, it’s essential to make commitments with each other. This can be done using the methodology described below.
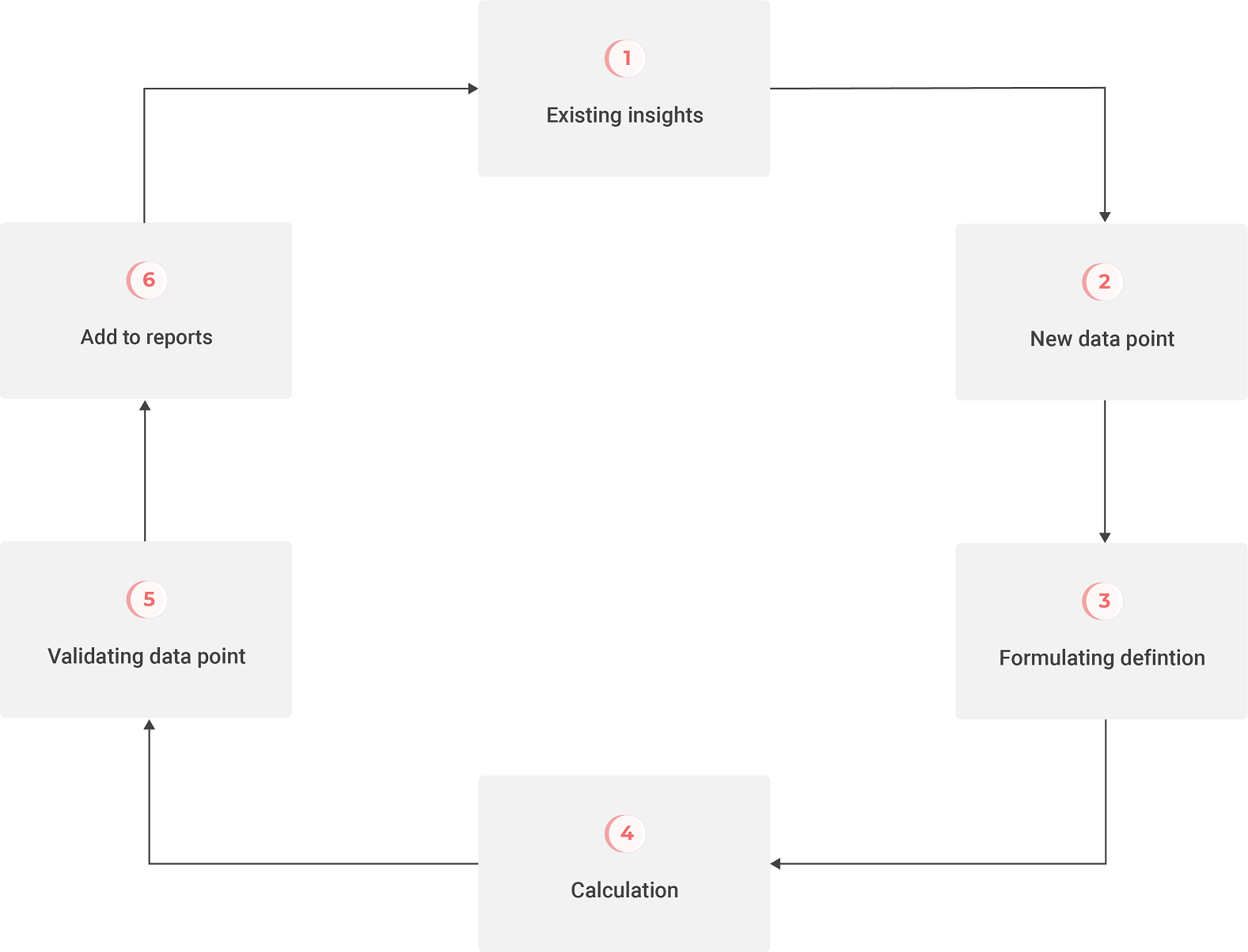 Figure 1: 6 steps to improve self-service BI
Figure 1: 6 steps to improve self-service BI
6 steps on the road to manageable self-service BI
The methodology covers the entire process of calculating, validating, and displaying the data. Using this methodology, you can quickly implement self-service BI, without sacrificing data purity. The various roles and responsibilities are clearly registered in this process. This is an important condition to avoiding most of the problems above.
- Existing insights. The cycle always starts with the existing, validated insights. These insights keep leading to new questions. In other words: this is an organic development process, where a new step is only undertaken when the previous version is working correctly.
- Suggesting a new data point. These new questions have to be made concrete (for example with a practical example). That makes it clear to everyone what the question means. It’s important that everyone involved agrees about the question to be solved, so that everyone can interpret the data correctly. That makes the next step easier.
- Formulating a definition. The question has to be turned into a definition. You might think these are one and the same, but they’re not. The definition has to consider the question of which data is available, and how it’s registered. The definition contains, for example, the exact names of the tables and columns the data is pulled from, and how they have to be processed together. This is important, because large organizations can make the same kind of data available in multiple places in the (enterprise) data warehouse, but with small differences in key places. It’s also important that the definition is relayed back to the stakeholders of step 2, and agreements have to be made again, to once again prevent wrong interpretations.
- Calculating. Once the definition is established, it can be calculated using the proper BI tools (see our BI Tools comparison guide to find out which tool is right for you).
- Validating the data point. As stated earlier, it can’t just be assumed that a data warehouse contains “pure” data. You also can’t assume that the data is exactly where you might expect it. The data has to be validated before releasing the calculated data. This can be done by those who registered the data, for example. This step is crucial, because the data is assumed to be true after this step. It can still happen that people don’t accept the data as true, especially when the numbers are disappointing. Positive numbers, on the other hand, are accepted as the truth, even if they’re not. But if this step is executed correctly, you can avoid debates about the origins and credibility of the numbers. That saves a lot of time!
- Adding to reports. Finally, the calculation can be re-added to the reports, and the cycle starts anew.
TIP: the definition and validation phases are crucial – never skip them.
Conclusion
The improvement method described above can be applied to different self-service levels. It’s possible to play every role for all six steps yourself. Of course, the method can also be used in a more traditional organization. A BI team could, for example, take care of the definition, calculation, and validation. The business intelligence manager then processes the calculated data in the reports. It also ensures that managers who prefer speed can no longer skip the crucial steps, such as definition and validation. To ensure that the steps are followed, someone should be appointed as the person responsible for every role. When implemented well, this method ensures a thorough foundation for a manageable self-service BI process.
BI self-service has important advantages such as being able to experiment quickly with potentially valuable data sets and being able to react faster to developments. But it also brings a number of risks to the organization. Even more easily than before, users can produce nonsense or end up reinventing the wheel. And multiple versions of the truth can arise simultaneously. Finally, BI self-service can lead to a patchwork of Business Intelligence software tools being created, which makes the manageable items more complex.
Broadly speaking, what it comes down to is that BI self-service has a lot of added value for the (experienced) analyst and seasoned end user. And it requires the BI manager to manage even more than before and to take more responsibility for the overall Business Intelligence process. If he or she is successful at it, BI self-service may be an excellent addition to the existing range of BI services.